Large-scale benchmarking for system identification methods
Written by Lanyue Zhang and Alan Kaptanoglu
In this notebook, we illustrate how to design a statistically robust benchmark for new innovations in system identification. To illustrate how this benchmark can be utilized, we perform the largest comparison to date of four popular algorithms (+ the weak formulation) for solving the sparse identification of nonlinear dynamics (SINDy) optimization.
In addition, we investigate how Pareto-optimal models generated from sparse system identification methods depend on the dynamical properties of the equations, finding to leading order that the performance of these methods is independent of the dynamical properties of these equations, including the amount of chaos, scale separation, degree of nonlinearity, and, surprisingly, the syntactic complexity.
We will use the dysts database, containingn over 100 chaotic systems. We will investigate a subset of the systems that are polynomially nonlinear, with highest polynomial degree <= 4. All of the following 70 systems are bounded and exhibit strange attractors.
An interactive version of this notebook is available on binder ![]()
[1]:
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import numpy as np
from scipy.integrate import odeint
from sklearn.metrics import mean_squared_error
from dysts.base import make_trajectory_ensemble
from dysts.base import get_attractor_list
import dysts.flows as flows
import dysts.datasets as datasets
from dysts.equation_utils import *
import time
from utils import *
# bad code but allows us to ignore warnings
import warnings
warnings.filterwarnings("ignore")
import pysindy as ps
Chaotic System Initialization
This experiment include 70 chaotic, polynomially nonlinear systems provided by the database from William Gilpin. “Chaos as an interpretable benchmark for forecasting and data-driven modelling” Advances in Neural Information Processing Systems (NeurIPS) 2021 https://arxiv.org/abs/2110.05266.
[2]:
t1 = time.time()
# Arneodo does not have the Lyapunov spectrum calculated so omit it.
# HindmarshRose and AtmosphericRegime seem to be poorly sampled
# by the dt and dominant time scales used in the database, so we omit them.
systems_list = [
"Aizawa", "Bouali2",
"GenesioTesi", "HyperBao", "HyperCai", "HyperJha",
"HyperLorenz", "HyperLu", "HyperPang", "Laser",
"Lorenz", "LorenzBounded", "MooreSpiegel", "Rossler", "ShimizuMorioka",
"HenonHeiles", "GuckenheimerHolmes", "Halvorsen", "KawczynskiStrizhak",
"VallisElNino", "RabinovichFabrikant", "NoseHoover", "Dadras", "RikitakeDynamo",
"NuclearQuadrupole", "PehlivanWei", "SprottTorus", "SprottJerk", "SprottA", "SprottB",
"SprottC", "SprottD", "SprottE", "SprottF", "SprottG", "SprottH", "SprottI", "SprottJ",
"SprottK", "SprottL", "SprottM", "SprottN", "SprottO", "SprottP", "SprottQ", "SprottR",
"SprottS", "Rucklidge", "Sakarya", "RayleighBenard", "Finance", "LuChenCheng",
"LuChen", "QiChen", "ZhouChen", "BurkeShaw", "Chen", "ChenLee", "WangSun", "DequanLi",
"NewtonLiepnik", "HyperRossler", "HyperQi", "Qi", "LorenzStenflo", "HyperYangChen",
"HyperYan", "HyperXu", "HyperWang", "Hadley",
]
alphabetical_sort = np.argsort(systems_list)
systems_list = np.array(systems_list)[alphabetical_sort]
# attributes list
attributes = [
"maximum_lyapunov_estimated",
"lyapunov_spectrum_estimated",
"embedding_dimension",
"parameters",
"dt",
"hamiltonian",
"period",
"unbounded_indices"
]
# Get attributes
all_properties = dict()
for i, equation_name in enumerate(systems_list):
eq = getattr(flows, equation_name)()
attr_vals = [getattr(eq, item, None) for item in attributes]
all_properties[equation_name] = dict(zip(attributes, attr_vals))
# Get training and testing trajectories for all the experimental systems
n = 1000 # Trajectories with 1000 points
pts_per_period = 100 # sample them with 100 points per period
n_trajectories = 5 # generate 5 trajectories starting from different initial conditions on the attractor
all_sols_train, all_t_train, all_sols_test, all_t_test = load_data(
systems_list, all_properties,
n=n, pts_per_period=pts_per_period,
random_bump=False, # optionally start with initial conditions pushed slightly off the attractor
include_transients=False, # optionally do high-resolution sampling at rate proportional to the dt parameter
n_trajectories=n_trajectories
)
t2 = time.time()
print('Took ', t2 - t1, ' seconds to load the systems')
0 Aizawa(name='Aizawa', params={'a': 0.95, 'b': 0.7, 'c': 0.6, 'd': 3.5, 'e': 0.25, 'f': 0.1}, random_state=None)
1 Bouali2(name='Bouali2', params={'a': 3.0, 'b': 2.2, 'bb': 0, 'c': 0, 'g': 1.0, 'm': -0.0026667, 'y0': 1.0}, random_state=None)
2 BurkeShaw(name='BurkeShaw', params={'e': 13, 'n': 10}, random_state=None)
3 Chen(name='Chen', params={'a': 35, 'b': 3, 'c': 28}, random_state=None)
4 ChenLee(name='ChenLee', params={'a': 5, 'b': -10, 'c': -0.38}, random_state=None)
5 Dadras(name='Dadras', params={'c': 2.0, 'e': 9.0, 'o': 2.7, 'p': 3.0, 'r': 1.7}, random_state=None)
6 DequanLi(name='DequanLi', params={'a': 40, 'c': 1.833, 'd': 0.16, 'eps': 0.65, 'f': 20, 'k': 55}, random_state=None)
7 Finance(name='Finance', params={'a': 0.001, 'b': 0.2, 'c': 1.1}, random_state=None)
8 GenesioTesi(name='GenesioTesi', params={'a': 0.44, 'b': 1.1, 'c': 1}, random_state=None)
9 GuckenheimerHolmes(name='GuckenheimerHolmes', params={'a': 0.4, 'b': 20.25, 'c': 3, 'd': 1.6, 'e': 1.7, 'f': 0.44}, random_state=None)
10 Hadley(name='Hadley', params={'a': 0.2, 'b': 4, 'f': 9, 'g': 1}, random_state=None)
11 Halvorsen(name='Halvorsen', params={'a': 1.4, 'b': 4}, random_state=None)
12 HenonHeiles(name='HenonHeiles', params={'lam': 1}, random_state=None)
13 HyperBao(name='HyperBao', params={'a': 36, 'b': 3, 'c': 20, 'd': 0.1, 'e': 21}, random_state=None)
14 HyperCai(name='HyperCai', params={'a': 27.5, 'b': 3, 'c': 19.3, 'd': 2.9, 'e': 3.3}, random_state=None)
15 HyperJha(name='HyperJha', params={'a': 10, 'b': 28, 'c': 2.667, 'd': 1.3}, random_state=None)
16 HyperLorenz(name='HyperLorenz', params={'a': 10, 'b': 2.667, 'c': 28, 'd': 1.1}, random_state=None)
17 HyperLu(name='HyperLu', params={'a': 36, 'b': 3, 'c': 20, 'd': 1.3}, random_state=None)
18 HyperPang(name='HyperPang', params={'a': 36, 'b': 3, 'c': 20, 'd': 2}, random_state=None)
19 HyperQi(name='HyperQi', params={'a': 50, 'b': 24, 'c': 13, 'd': 8, 'e': 33, 'f': 30}, random_state=None)
20 HyperRossler(name='HyperRossler', params={'a': 0.25, 'b': 3.0, 'c': 0.5, 'd': 0.05}, random_state=None)
21 HyperWang(name='HyperWang', params={'a': 10, 'b': 40, 'c': 2.5, 'd': 10.6, 'e': 4}, random_state=None)
22 HyperXu(name='HyperXu', params={'a': 10, 'b': 40, 'c': 2.5, 'd': 2, 'e': 16}, random_state=None)
23 HyperYan(name='HyperYan', params={'a': 37, 'b': 3, 'c': 26, 'd': 38}, random_state=None)
24 HyperYangChen(name='HyperYangChen', params={'a': 30, 'b': 3, 'c': 35, 'd': 8}, random_state=None)
25 KawczynskiStrizhak(name='KawczynskiStrizhak', params={'beta': -0.4, 'gamma': 0.49, 'kappa': 0.2, 'mu': 2.1}, random_state=None)
26 Laser(name='Laser', params={'a': 10.0, 'b': 1.0, 'c': 5.0, 'd': -1.0, 'h': -5.0, 'k': -6.0}, random_state=None)
27 Lorenz(name='Lorenz', params={'beta': 2.667, 'rho': 28, 'sigma': 10}, random_state=None)
28 LorenzBounded(name='LorenzBounded', params={'beta': 2.667, 'r': 64, 'rho': 28, 'sigma': 10}, random_state=None)
29 LorenzStenflo(name='LorenzStenflo', params={'a': 2, 'b': 0.7, 'c': 26, 'd': 1.5}, random_state=None)
30 LuChen(name='LuChen', params={'a': 36, 'b': 3, 'c': 18}, random_state=None)
31 LuChenCheng(name='LuChenCheng', params={'a': -10, 'b': -4, 'c': 18.1}, random_state=None)
32 MooreSpiegel(name='MooreSpiegel', params={'a': 10, 'b': 4, 'eps': 9}, random_state=None)
33 NewtonLiepnik(name='NewtonLiepnik', params={'a': 0.4, 'b': 0.175}, random_state=None)
34 NoseHoover(name='NoseHoover', params={'a': 1.5}, random_state=None)
35 NuclearQuadrupole(name='NuclearQuadrupole', params={'a': 1.0, 'b': 0.55, 'd': 0.4}, random_state=None)
36 PehlivanWei(name='PehlivanWei', params={}, random_state=None)
37 Qi(name='Qi', params={'a': 45, 'b': 10, 'c': 1, 'd': 10}, random_state=None)
38 QiChen(name='QiChen', params={'a': 38, 'b': 2.666, 'c': 80}, random_state=None)
39 RabinovichFabrikant(name='RabinovichFabrikant', params={'a': 1.1, 'g': 0.87}, random_state=None)
40 RayleighBenard(name='RayleighBenard', params={'a': 30, 'b': 5, 'r': 18}, random_state=None)
41 RikitakeDynamo(name='RikitakeDynamo', params={'a': 1.0, 'mu': 1.0}, random_state=None)
42 Rossler(name='Rossler', params={'a': 0.2, 'b': 0.2, 'c': 5.7}, random_state=None)
43 Rucklidge(name='Rucklidge', params={'a': 2.0, 'b': 6.7}, random_state=None)
44 Sakarya(name='Sakarya', params={'a': -1.0, 'b': 1.0, 'c': 1.0, 'h': 1.0, 'p': 1.0, 'q': 0.4, 'r': 0.3, 's': 1.0}, random_state=None)
45 ShimizuMorioka(name='ShimizuMorioka', params={'a': 0.85, 'b': 0.5}, random_state=None)
46 SprottA(name='SprottA', params={}, random_state=None)
47 SprottB(name='SprottB', params={}, random_state=None)
48 SprottC(name='SprottC', params={}, random_state=None)
49 SprottD(name='SprottD', params={}, random_state=None)
50 SprottE(name='SprottE', params={}, random_state=None)
51 SprottF(name='SprottF', params={'a': 0.5}, random_state=None)
52 SprottG(name='SprottG', params={'a': 0.4}, random_state=None)
53 SprottH(name='SprottH', params={'a': 0.5}, random_state=None)
54 SprottI(name='SprottI', params={'a': 0.2}, random_state=None)
55 SprottJ(name='SprottJ', params={}, random_state=None)
56 SprottJerk(name='SprottJerk', params={'mu': 2.017}, random_state=None)
57 SprottK(name='SprottK', params={'a': 0.3}, random_state=None)
58 SprottL(name='SprottL', params={'a': 0.9, 'b': 3.9}, random_state=None)
59 SprottM(name='SprottM', params={'a': 1.7}, random_state=None)
60 SprottN(name='SprottN', params={}, random_state=None)
61 SprottO(name='SprottO', params={'a': 2.7}, random_state=None)
62 SprottP(name='SprottP', params={'a': 2.7}, random_state=None)
63 SprottQ(name='SprottQ', params={'a': 3.1, 'b': 0.5}, random_state=None)
64 SprottR(name='SprottR', params={'a': 0.9, 'b': 0.4}, random_state=None)
65 SprottS(name='SprottS', params={}, random_state=None)
66 SprottTorus(name='SprottTorus', params={}, random_state=None)
67 VallisElNino(name='VallisElNino', params={'b': 102, 'c': 3, 'p': 0}, random_state=None)
68 WangSun(name='WangSun', params={'a': 0.2, 'b': -0.01, 'd': -0.4, 'e': -1.0, 'f': -1.0, 'q': 1.0}, random_state=None)
69 ZhouChen(name='ZhouChen', params={'a': 2.97, 'b': 0.15, 'c': -3.0, 'd': 1, 'e': -8.78}, random_state=None)
Took 517.0647609233856 seconds to load the systems
Calculate the true coefficients
The dysts database has functionality to read in all the dysts database functions defining the systems of ODEs, and extracts all the coefficients. We can use this to make a big matrix representing all the true coefficients in all the dynamical systems, which can be used to judge the quality of our system identification results later.
[3]:
num_attractors = len(systems_list)
# Calculate some dynamical properties
lyap_list = []
dimension_list = []
param_list = []
# Calculate various definitions of scale separation
scale_list_avg = []
scale_list = []
linear_scale_list = []
for system in systems_list:
lyap_list.append(all_properties[system]['maximum_lyapunov_estimated'])
dimension_list.append(all_properties[system]['embedding_dimension'])
param_list.append(all_properties[system]['parameters'])
# Ratio of dominant (average) to smallest timescales
scale_list_avg.append(all_properties[system]['period'] / all_properties[system]['dt'])
# Get the true coefficients for each system
true_coefficients = make_dysts_true_coefficients(systems_list,
all_sols_train,
dimension_list,
param_list)
# Whether to use the weak formulation of SINDy or not
weak_form = False
# Need to reorder the coefficients if using the weak form to compare with analytic,
# because weak formulation of the SINDy library is in a different order than the
# PolynomialLibrary with degree = 4
if weak_form:
# reordering to use if system is 3D
reorder1 = np.array([ 0, 1, 2, 3, 4, 7, 9, 5, 6, 8, 10, 16, 19, 11, 12, 17, 13,
15, 18, 14, 20, 30, 34, 21, 22, 31, 26, 29, 33, 23, 25, 32, 27, 28,
24], dtype=int)
# reordering to use if system is 4D
reorder2 = np.array([ 0, 1, 2, 3, 4, 5, 9, 12, 14, 6, 7, 8, 10, 11, 13, 15, 25,
31, 34, 16, 17, 18, 26, 27, 32, 19, 22, 24, 28, 30, 33, 20, 21, 23,
29, 35, 55, 65, 69, 36, 37, 38, 56, 57, 66, 45, 51, 54, 61, 64, 68,
39, 42, 44, 58, 60, 67, 46, 47, 52, 62, 48, 50, 53, 63, 40, 41, 43,
59, 49], dtype=int)
for i, system in enumerate(systems_list):
if dimension_list[i] == 3:
true_coefficients[i] = true_coefficients[i][:, reorder1]
else:
true_coefficients[i] = true_coefficients[i][:, reorder2]
# Compute all the different nonlinear terms from the true coefficients
nonlinearities = nonlinear_terms_from_coefficients(true_coefficients)
# Compute various dynamical properties
count = 0
for i, system in enumerate(systems_list):
linear_coefs = true_coefficients[i][:, :dimension_list[i]]
max_linear = np.max(abs(linear_coefs))
min_linear = np.min(abs(linear_coefs[linear_coefs != 0.0]))
linear_scale_list.append(max_linear / min_linear)
sorted_spectrum = np.sort((np.array(all_properties[system]['lyapunov_spectrum_estimated'])))
lambda_max = sorted_spectrum[-1]
lambda_min = sorted_spectrum[0]
if np.all(np.array(all_properties[system]['lyapunov_spectrum_estimated'][0:2]) > 0.0):
count += 1
scale_list.append(lambda_max / lambda_min)
print('Number of hyper-chaotic (at least two positive Lyapunov exponents) systems = ', count)
# Lastly, compute the syntactic complexity of all the dynamical system equations,
# as measured by the mean-equation description length (MEDL). More informationn
# can be found in the AI Feynman 2.0 paper
medl_list = compute_medl(systems_list, param_list)
Number of hyper-chaotic (at least two positive Lyapunov exponents) systems = 51
[4]:
from matplotlib.colors import LogNorm
# Shorten some of the dynamical system names to make nicer plots
systems_list_cleaned = []
for i, system in enumerate(systems_list):
if system == "GuckenheimerHolmes":
systems_list_cleaned.append("GuckenHolmes")
elif system == "NuclearQuadrupole":
systems_list_cleaned.append("NuclearQuad")
elif system == "RabinovichFabrikant":
systems_list_cleaned.append("RabFabrikant")
elif system == "KawczynskiStrizhak":
systems_list_cleaned.append("KawcStrizhak")
elif system == "RikitakeDynamo":
systems_list_cleaned.append("RikiDynamo")
elif system == "ShimizuMorioka":
systems_list_cleaned.append("ShMorioka")
elif system == "HindmarshRose":
systems_list_cleaned.append("Hindmarsh")
elif system == "RayleighBenard":
systems_list_cleaned.append("RayBenard")
else:
systems_list_cleaned.append(system)
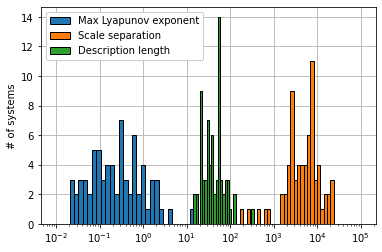
# Make two summary plots of all the dynamical system properties
plt.figure()
medl_levels = np.logspace(1, 3, 40)
lyap_levels = np.logspace(-2, 2, 40)
scale_levels = np.logspace(2, 5, 40)
plt.hist(lyap_list, bins=lyap_levels, ec='k')
plt.hist(scale_list_avg, bins=scale_levels, ec='k')
plt.hist(medl_list, bins=medl_levels, ec='k')
plt.xlabel('')
plt.ylabel('# of systems')
plt.legend(['Max Lyapunov exponent', 'Scale separation', 'Description length'],
framealpha=1.0)
plt.xscale('log')
plt.grid(True)
ax = plt.gca()
ax.set_axisbelow(True)
plt.figure(figsize=(30, 6))
plt.imshow(nonlinearities.T, aspect='equal', origin='lower', cmap='Oranges')
plt.xticks(np.arange(num_attractors), rotation="vertical", fontsize=20)
ax = plt.gca()
plt.xlim(-0.5, num_attractors - 0.5)
ax.set_xticklabels(np.array(systems_list_cleaned))
plt.yticks(np.arange(5), fontsize=22)
plt.colorbar(shrink=0.3, pad=0.01).ax.tick_params(labelsize=16)
plt.ylabel('Poly\n order', rotation=0, fontsize=22)
ax.yaxis.set_label_coords(-0.045, 0.3)

Trajectory Visualization
Visualizing the training and testing trajectories helps us verify if the time series data is coming from the strange attractors or from transients in the evolution.
[5]:
# add some Gaussian noise
noise_level = 0.0
# Plot the training and testing trajectories for all the chaotic systems
num_cols = 5
num_rows = int(np.ceil(len(all_sols_train) / num_cols))
plt.figure(figsize=(num_cols * 2, num_rows * 2))
gs = plt.matplotlib.gridspec.GridSpec(num_rows, num_cols)
gs.update(wspace=0.0, hspace=0.0)
for i, attractor_name in enumerate(systems_list):
x_train = np.copy(all_sols_train[attractor_name][0])
rmse = mean_squared_error(x_train, np.zeros(x_train.shape), squared=False)
x_train += np.random.normal(0, rmse / 100.0 * noise_level, x_train.shape)
x_test = all_sols_test[attractor_name][0]
t_train = all_t_train[attractor_name]
t_test = all_t_test[attractor_name]
plt.subplot(gs[i])
plt.plot(x_train[:, 0], x_train[:, 1], 'k', linewidth=1)
plt.plot(x_test[:, 0], x_test[:, 1], 'r', linewidth=1)
ax = plt.gca()
plt.yticks([])
plt.xticks([])
xmax = np.max(x_train[:, 0])
xmin = np.min(x_train[:, 0])
ymax = np.max(x_train[:, 1])
ymin = np.min(x_train[:, 1])
facx = (xmax - xmin) / 3
facy = (ymax - ymin) / 3
plt.xlim(xmin - facx, xmax + facx)
plt.ylim(ymin - facy, ymax + facy)
plt.text(0.035, 0.85, systems_list_cleaned[i], transform=ax.transAxes, fontsize=12)
if i == 65:
plt.xlabel(r'$x_1$', fontsize=18)
plt.ylabel(r'$x_2$', fontsize=18, rotation=0, )
ax.yaxis.set_label_coords(-0.15,0.45)
plt.savefig('trajectories.pdf')
plt.show()

Hyperparameter scans using the AIC metric
Below, we perform hyperparameter scans where the best model at each iteration is the one that minimizes the finite-sampled-corrected AIC on a test trajectory (see Mangan, Niall M., et al. “Model selection for dynamical systems via sparse regression and information criteria.” Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences 473.2204 (2017): 20170009.). Unlike previous work, at every value of the hyperparameter, we generate \(n_\text{models}\) models, and take as our metric the average AIC over the 10 models. The default is to scan 300 values of the hyperparameter, so in total we compute 300 x \(n_\text{models}\) x 70 = 210,000 models!
[6]:
algorithm = "STLSQ"
# if using the weak form, this makes the Pareto curve based on the "strong" or regular RMSE error
# instead of the RMSE error of the weak formulation.
strong_rmse = True
t1 = time.time()
# Note, defaults to using the AIC to decide the Pareto-optimal model
n_models = 10
(xdot_rmse_errors, xdot_coef_errors, AIC, x_dot_tests, x_dot_test_preds,
predicted_coefficients, best_threshold_values, models, condition_numbers) = Pareto_scan_ensembling(
systems_list, dimension_list, true_coefficients,
all_sols_train, all_t_train, all_sols_test, all_t_test,
normalize_columns=False, # whether to normalize the SINDy matrix
noise_level=noise_level, # amount of noise to add to the training data
n_models=n_models, # number of models to train using EnsemblingOptimizer functionality
n_subset=int(0.5 * len(all_t_train['HyperBao'][0])), # subsample 50% of the training data for each model
replace=False, # Do the subsampling without replacement
weak_form=weak_form, # use the weak form or not
algorithm=algorithm, # optimization algorithm
strong_rmse=strong_rmse, # use the strong rmse with the weak form or not
)
t2 = time.time()
print('Total time to compute = ', t2 - t1, ' seconds')
# print('Condition numbers = ', condition_numbers)
0 / 70 , System = Aizawa
1 / 70 , System = Bouali2
2 / 70 , System = BurkeShaw
3 / 70 , System = Chen
4 / 70 , System = ChenLee
5 / 70 , System = Dadras
6 / 70 , System = DequanLi
7 / 70 , System = Finance
8 / 70 , System = GenesioTesi
9 / 70 , System = GuckenheimerHolmes
10 / 70 , System = Hadley
11 / 70 , System = Halvorsen
12 / 70 , System = HenonHeiles
13 / 70 , System = HyperBao
14 / 70 , System = HyperCai
15 / 70 , System = HyperJha
16 / 70 , System = HyperLorenz
17 / 70 , System = HyperLu
18 / 70 , System = HyperPang
19 / 70 , System = HyperQi
20 / 70 , System = HyperRossler
21 / 70 , System = HyperWang
22 / 70 , System = HyperXu
23 / 70 , System = HyperYan
24 / 70 , System = HyperYangChen
25 / 70 , System = KawczynskiStrizhak
26 / 70 , System = Laser
27 / 70 , System = Lorenz
28 / 70 , System = LorenzBounded
29 / 70 , System = LorenzStenflo
30 / 70 , System = LuChen
31 / 70 , System = LuChenCheng
32 / 70 , System = MooreSpiegel
33 / 70 , System = NewtonLiepnik
34 / 70 , System = NoseHoover
35 / 70 , System = NuclearQuadrupole
36 / 70 , System = PehlivanWei
37 / 70 , System = Qi
38 / 70 , System = QiChen
39 / 70 , System = RabinovichFabrikant
40 / 70 , System = RayleighBenard
41 / 70 , System = RikitakeDynamo
42 / 70 , System = Rossler
43 / 70 , System = Rucklidge
44 / 70 , System = Sakarya
45 / 70 , System = ShimizuMorioka
46 / 70 , System = SprottA
47 / 70 , System = SprottB
48 / 70 , System = SprottC
49 / 70 , System = SprottD
50 / 70 , System = SprottE
51 / 70 , System = SprottF
52 / 70 , System = SprottG
53 / 70 , System = SprottH
54 / 70 , System = SprottI
55 / 70 , System = SprottJ
56 / 70 , System = SprottJerk
57 / 70 , System = SprottK
58 / 70 , System = SprottL
59 / 70 , System = SprottM
60 / 70 , System = SprottN
61 / 70 , System = SprottO
62 / 70 , System = SprottP
63 / 70 , System = SprottQ
64 / 70 , System = SprottR
65 / 70 , System = SprottS
66 / 70 , System = SprottTorus
67 / 70 , System = VallisElNino
68 / 70 , System = WangSun
69 / 70 , System = ZhouChen
Total time = 1738.8008062839508
Total time to compute = 1738.801950931549 seconds
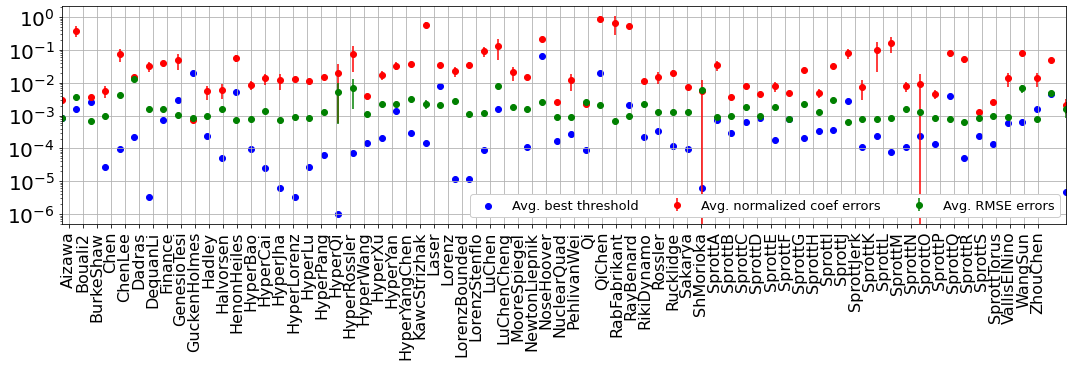
Normalized Error
Below, we compute the total normalized coefficient errors, RMSE errors on the \(\dot{\mathbf X}\) testing trajectories, and best thresholds for each system. For the weak form, some sorting and additional metrics are computed.
[7]:
avg_rmse_error = np.zeros(num_attractors)
std_rmse_error = np.zeros(num_attractors)
coef_avg_error = np.zeros((num_attractors, n_models))
best_thresholds = np.zeros(num_attractors)
for i, attractor_name in enumerate(systems_list):
for j in range(n_models):
coef_avg_error[i, j] = total_coefficient_error_normalized(
true_coefficients[i],
np.array(predicted_coefficients[attractor_name])[0, j, :, :]
)
avg_rmse_error[i] = np.mean(np.ravel(abs(np.array(xdot_rmse_errors[attractor_name]))))
std_rmse_error[i] = np.std(np.ravel(abs(np.array(xdot_rmse_errors[attractor_name]))))
best_thresholds[i] = best_threshold_values[attractor_name][0]
if weak_form:
rmse_error_strong = {}
for system in systems_list:
rmse_error_strong[system] = list()
# Compute the "strong" RMSE errors using a non-weak model, since otherwise
# the RMSE from the weak model is computed from the subdomains. This is
# normally fine, but we would like to compare the same RMSE error between the
# traditional and weak SINDy methods.
models_strong = []
for i, attractor_name in enumerate(systems_list):
x_test_list = []
t_test_list = []
for j in range(n_trajectories):
x_test_list.append(all_sols_test[attractor_name][j])
t_test_list.append(all_t_test[attractor_name][j])
poly_lib = ps.PolynomialLibrary(degree=4)
if dimension_list[i] == 3:
feature_names = ["x", "y", "z"]
else:
feature_names = ["x", "y", "z", "w"]
optimizer = ps.STLSQ(
threshold=0.0,
alpha=1e-5,
max_iter=100,
normalize_columns=False,
ridge_kw={"tol": 1e-10},
)
model = ps.SINDy(
feature_library=poly_lib,
optimizer=optimizer,
feature_names=feature_names,
)
model.fit(np.zeros(all_sols_train[attractor_name][0].shape))
rmses=[]
for coef_temp in predicted_coefficients[attractor_name][0]:
if dimension_list[i] == 3:
model.optimizer.coef_ = coef_temp[:, :]
else:
model.optimizer.coef_ = coef_temp[:, :]
# model.print()
models_strong.append(model)
x_dot_test = model.differentiate(x_test_list, t=t_test_list, multiple_trajectories=True)
x_dot_test_pred = model.predict(x_test_list, multiple_trajectories=True)
rmses=rmses+[normalized_RMSE(
np.array(x_dot_test).reshape(n_trajectories * n, dimension_list[i]),
np.array(x_dot_test_pred).reshape(n_trajectories * n, dimension_list[i]),
)]
rmse_error_strong[attractor_name].append(np.mean(rmses))
Plot overall performance across dynamical systems
[8]:
plt.figure(figsize=(18, 4))
plt.errorbar(
np.linspace(-0.5, num_attractors + 1, num_attractors),
np.mean(coef_avg_error, axis=-1),
np.std(coef_avg_error, axis=-1),
fmt="ro",
label="Avg. normalized coef errors",
)
plt.errorbar(
np.linspace(-0.5, num_attractors + 1, num_attractors),
avg_rmse_error,
std_rmse_error,
fmt="go",
label="Avg. RMSE errors",
)
plt.scatter(
np.linspace(-0.5, num_attractors + 1, num_attractors),
best_thresholds, c="b", marker='o',
label="Avg. best threshold"
)
plt.grid(True)
plt.yscale("log")
plt.legend(
framealpha=1.0,
ncol=4,
fontsize=13,
)
ax = plt.gca()
plt.xticks(np.arange(num_attractors), rotation="vertical", fontsize=16)
plt.xlim(-0.5, num_attractors + 1)
ax.set_xticklabels(np.array(systems_list_cleaned))
plt.yticks(fontsize=20)
plt.show()
Plot the true and predicted \(\dot{\mathbf x}\) trajectories for all the chaotic systems
We find that the fits are very strong on the testing data, but the more stringent test (after this) will be to integrate new trajectories with new initial conditions, using our best SINDy models.
[9]:
num_cols = 5
num_rows = int(np.ceil(len(all_sols_train) / num_cols))
fig = plt.figure(figsize=(num_cols * 2, num_rows * 2))
gs = plt.matplotlib.gridspec.GridSpec(num_rows, num_cols)
gs.update(wspace=0.0, hspace=0.05)
if weak_form and not strong_rmse:
ntime = models[i].feature_library.K
else:
ntime = len(all_t_train['Aizawa'][0])
for i, attractor_name in enumerate(systems_list):
x_dot_test = np.array(x_dot_tests[i])
x_dot_test_pred = np.array(x_dot_test_preds[i]).reshape(n_trajectories, ntime, dimension_list[i])
plt.subplot(gs[i])
for j in range(n_trajectories):
plt.plot(x_dot_test[j, :, 0], x_dot_test[j, :, 1], 'k', linewidth=0.25)
plt.plot(x_dot_test_pred[j, :, 0], x_dot_test_pred[j, :, 1], 'r', linewidth=0.25)
plt.title(attractor_name, y=-0.1, fontsize=14)
plt.gca().axis('off')

Very stringent performance test for our best SINDy models
We will integrate new trajectories using 10 new initial conditions and see if the SINDy models reproduce the correct strange attractor(s) for each chaotic system in the database.
[10]:
t1 = time.time()
num_test_trajectories = 10
test_trajectories, test_trajectories_time = make_test_trajectories(
systems_list,
all_properties,
n=n,
pts_per_period=pts_per_period,
random_bump=False, # pushes the initial condition to be slightly off the attractor
include_transients=False, # overwrites pts_per_period in order to sample at very high resolution
n_trajectories=num_test_trajectories,
)
Plot the trajectory results for 10 new initial conditions
Note that this is only sensible if we are not using the weak form, since the weak form functionality in the PySINDy code doesn’t yet have functionality for integrating new trajectories.
[11]:
if not weak_form:
num_cols = 5
num_rows = int(np.ceil(len(all_sols_train) / num_cols))
plt.figure(figsize=(num_cols * 2, num_rows * 2))
gs = plt.matplotlib.gridspec.GridSpec(num_rows, num_cols)
gs.update(wspace=0.0, hspace=0.0)
for i, attractor in enumerate(systems_list):
print(i, attractor)
fig = plt.subplot(gs[i])
num_bounded = num_test_trajectories
for j in range(num_test_trajectories):
plt.plot(test_trajectories[attractor][:, j, 0], test_trajectories[attractor][:, j, 1], 'k') #, test_trajectories[attractor][:, j, 2], 'k')
x0 = test_trajectories[attractor][0, j, :] + (np.random.rand(dimension_list[i]) - 0.5) * np.linalg.norm(test_trajectories[attractor][:, j, :]) / 100.0
models[i].feature_library.fit(np.zeros(dimension_list[i]))
x_pred = models[i].simulate(
x0,
t=test_trajectories_time[attractor][:, j],
integrator='odeint'
)
if np.linalg.norm(x_pred) > np.linalg.norm(test_trajectories[attractor][:, j, 0]) * 10:
num_bounded -= 1
else:
plt.plot(x_pred[:, 0], x_pred[:, 1], 'r')
ax = plt.gca()
fig.patch.set_facecolor('grey')
fig.patch.set_alpha(1 - (num_bounded / num_test_trajectories))
plt.yticks([])
plt.xticks([])
xmax = np.max(test_trajectories[attractor][:, :, 0])
xmin = np.min(test_trajectories[attractor][:, :, 0])
ymax = np.max(test_trajectories[attractor][:, :, 1])
ymin = np.min(test_trajectories[attractor][:, :, 1])
facx = (xmax - xmin) / 3
facy = (ymax - ymin) / 3
plt.xlim(xmin - facx, xmax + facx)
plt.ylim(ymin - facy, ymax + facy)
plt.text(0.035, 0.85, systems_list_cleaned[i], transform=ax.transAxes, fontsize=12)
if i == 65:
plt.xlabel(r'$x_1$', fontsize=18)
plt.ylabel(r'$x_2$', fontsize=18, rotation=0, )
ax.yaxis.set_label_coords(-0.15,0.45)
plt.savefig('final_trajectories_zero_noise.pdf')
t2 = time.time()
print('Integrating all these new initial conditions took t = ', t2 - t1, ' seconds')
0 Aizawa
1 Bouali2
2 BurkeShaw
3 Chen
4 ChenLee
5 Dadras
6 DequanLi
7 Finance
8 GenesioTesi
9 GuckenheimerHolmes
10 Hadley
11 Halvorsen
12 HenonHeiles
13 HyperBao
14 HyperCai
15 HyperJha
16 HyperLorenz
17 HyperLu
18 HyperPang
19 HyperQi
20 HyperRossler
21 HyperWang
22 HyperXu
23 HyperYan
24 HyperYangChen
25 KawczynskiStrizhak
26 Laser
27 Lorenz
28 LorenzBounded
29 LorenzStenflo
30 LuChen
31 LuChenCheng
32 MooreSpiegel
33 NewtonLiepnik
34 NoseHoover
35 NuclearQuadrupole
36 PehlivanWei
37 Qi
38 QiChen
39 RabinovichFabrikant
40 RayleighBenard
41 RikitakeDynamo
42 Rossler
43 Rucklidge
44 Sakarya
45 ShimizuMorioka
46 SprottA
47 SprottB
48 SprottC
49 SprottD
50 SprottE
51 SprottF
52 SprottG
53 SprottH
54 SprottI
55 SprottJ
56 SprottJerk
57 SprottK
58 SprottL
59 SprottM
60 SprottN
61 SprottO
62 SprottP
63 SprottQ
64 SprottR
65 SprottS
66 SprottTorus
67 VallisElNino
68 WangSun
69 ZhouChen
Integrating all these new initial conditions took t = 4553.888377189636 seconds
