Feature Overview
This notebook provides a simple overview of the basic functionality of PySINDy. In addition to demonstrating the basic usage for fitting a SINDy model, we demonstrate several means of customizing the SINDy fitting procedure. These include different forms of input data, different optimization methods, different differentiation methods, and custom feature libraries.
An interactive version of this notebook is available on binder. ![]()
[1]:
import warnings
from contextlib import contextmanager
from copy import copy
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
from scipy.integrate import solve_ivp
from scipy.linalg import LinAlgWarning
from sklearn.exceptions import ConvergenceWarning
from sklearn.linear_model import Lasso
import pysindy as ps
from pysindy.utils import enzyme
from pysindy.utils import lorenz
from pysindy.utils import lorenz_control
if __name__ != "testing":
t_end_train = 10
t_end_test = 15
else:
t_end_train = 0.04
t_end_test = 0.04
data = (Path() / "../data").resolve()
@contextmanager
def ignore_specific_warnings():
filters = copy(warnings.filters)
warnings.filterwarnings("ignore", category=ConvergenceWarning)
warnings.filterwarnings("ignore", category=LinAlgWarning)
warnings.filterwarnings("ignore", category=UserWarning)
yield
warnings.filters = filters
if __name__ == "testing":
import sys
import os
sys.stdout = open(os.devnull, "w")
[2]:
# Seed the random number generators for reproducibility
np.random.seed(100)
A note on solve_ivp vs odeint before we continue
The default solver for solve_ivp is a Runga-Kutta method (RK45) but this seems to work quite poorly on a number of these examples, likely because they are multi-scale and chaotic. Instead, the LSODA method seems to perform quite well (ironically this is the default for the older odeint method). This is a nice reminder that system identification is important to get the right model, but a good integrator is still needed at the end!
[3]:
# Initialize integrator keywords for solve_ivp to replicate the odeint defaults
integrator_keywords = {}
integrator_keywords["rtol"] = 1e-12
integrator_keywords["method"] = "LSODA"
integrator_keywords["atol"] = 1e-12
Basic usage
We will fit a SINDy model to the famous Lorenz system:
Train the model
[4]:
# Generate measurement data
dt = 0.002
t_train = np.arange(0, t_end_train, dt)
x0_train = [-8, 8, 27]
t_train_span = (t_train[0], t_train[-1])
x_train = solve_ivp(
lorenz, t_train_span, x0_train, t_eval=t_train, **integrator_keywords
).y.T
[5]:
# Instantiate and fit the SINDy model
model = ps.SINDy()
model.fit(x_train, t=dt)
model.print()
(x0)' = -9.999 x0 + 9.999 x1
(x1)' = 27.992 x0 + -0.999 x1 + -1.000 x0 x2
(x2)' = -2.666 x2 + 1.000 x0 x1
Assess results on a test trajectory
[6]:
# Evolve the Lorenz equations in time using a different initial condition
t_test = np.arange(0, t_end_test, dt)
x0_test = np.array([8, 7, 15])
t_test_span = (t_test[0], t_test[-1])
x_test = solve_ivp(
lorenz, t_test_span, x0_test, t_eval=t_test, **integrator_keywords
).y.T
# Compare SINDy-predicted derivatives with finite difference derivatives
print("Model score: %f" % model.score(x_test, t=dt))
Model score: 1.000000
Predict derivatives with learned model
[7]:
# Predict derivatives using the learned model
x_dot_test_predicted = model.predict(x_test)
# Compute derivatives with a finite difference method, for comparison
x_dot_test_computed = model.differentiation_method(x_test, t=dt)
fig, axs = plt.subplots(x_test.shape[1], 1, sharex=True, figsize=(7, 9))
for i in range(x_test.shape[1]):
axs[i].plot(t_test, x_dot_test_computed[:, i], "k", label="numerical derivative")
axs[i].plot(t_test, x_dot_test_predicted[:, i], "r--", label="model prediction")
axs[i].legend()
axs[i].set(xlabel="t", ylabel=r"$\dot x_{}$".format(i))
fig.show()
/tmp/ipykernel_167005/962476686.py:13: UserWarning: FigureCanvasAgg is non-interactive, and thus cannot be shown
fig.show()

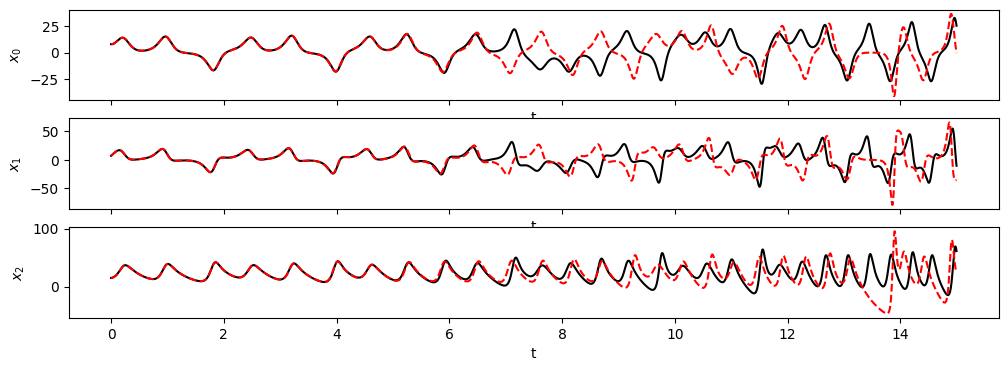
Simulate forward in time
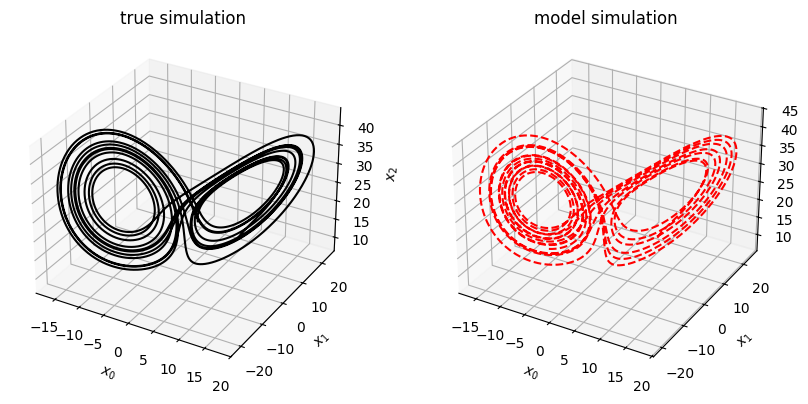
[8]:
# Evolve the new initial condition in time with the SINDy model
x_test_sim = model.simulate(x0_test, t_test)
fig, axs = plt.subplots(x_test.shape[1], 1, sharex=True, figsize=(7, 9))
for i in range(x_test.shape[1]):
axs[i].plot(t_test, x_test[:, i], "k", label="true simulation")
axs[i].plot(t_test, x_test_sim[:, i], "r--", label="model simulation")
axs[i].legend()
axs[i].set(xlabel="t", ylabel="$x_{}$".format(i))
fig = plt.figure(figsize=(10, 4.5))
ax1 = fig.add_subplot(121, projection="3d")
ax1.plot(x_test[:, 0], x_test[:, 1], x_test[:, 2], "k")
ax1.set(xlabel="$x_0$", ylabel="$x_1$", zlabel="$x_2$", title="true simulation")
ax2 = fig.add_subplot(122, projection="3d")
ax2.plot(x_test_sim[:, 0], x_test_sim[:, 1], x_test_sim[:, 2], "r--")
ax2.set(xlabel="$x_0$", ylabel="$x_1$", zlabel="$x_2$", title="model simulation")
fig.show()
/tmp/ipykernel_167005/1461697121.py:20: UserWarning: FigureCanvasAgg is non-interactive, and thus cannot be shown
fig.show()

Optimization options
In this section we provide examples of different parameters accepted by the built-in sparse regression optimizers STLSQ, SR3, ConstrainedSR3, MIOSR, SSR, and FROLS. The Trapping optimizer is not straightforward to use; please check out Example 8 for some examples. We also show how to use a scikit-learn sparse regressor with PySINDy.
STLSQ - change parameters
[9]:
stlsq_optimizer = ps.STLSQ(threshold=0.01, alpha=0.5)
model = ps.SINDy(optimizer=stlsq_optimizer)
model.fit(x_train, t=dt)
model.print()
(x0)' = -9.999 x0 + 9.999 x1
(x1)' = 27.992 x0 + -0.999 x1 + -1.000 x0 x2
(x2)' = -2.666 x2 + 1.000 x0 x1
STLSQ - verbose (print out optimization terms at each iteration)
The same verbose option is available with all the other optimizers. For optimizers that use the CVXPY package, there is additional boolean flag, verbose_cvxpy, that decides whether or not CVXPY solves will also be verbose.
[10]:
stlsq_optimizer = ps.STLSQ(threshold=0.01, alpha=0.5, verbose=True)
model = ps.SINDy(optimizer=stlsq_optimizer)
model.fit(x_train, t=dt)
model.print()
Iteration ... |y - Xw|^2 ... a * |w|_2 ... |w|_0 ... Total error: |y - Xw|^2 + a * |w|_2
0 ... 3.1040e+01 ... 4.9652e+02 ... 8 ... 5.2756e+02
1 ... 1.1797e+00 ... 4.9674e+02 ... 7 ... 4.9792e+02
2 ... 1.1712e+00 ... 4.9675e+02 ... 7 ... 4.9792e+02
(x0)' = -9.999 x0 + 9.999 x1
(x1)' = 27.992 x0 + -0.999 x1 + -1.000 x0 x2
(x2)' = -2.666 x2 + 1.000 x0 x1
SR3
[11]:
sr3_optimizer = ps.SR3(reg_weight_lam=0.1, regularizer="l1")
model = ps.SINDy(optimizer=sr3_optimizer)
model.fit(x_train, t=dt)
model.print()
(x0)' = -9.905 x0 + 9.903 x1
(x1)' = 27.891 x0 + -0.898 x1 + -0.900 x0 x2
(x2)' = -2.566 x2 + 0.899 x0 x1
SR3 - with trimming
SR3 is capable of automatically trimming outliers from training data. Specifying the parameter trimming_fraction tells the method what fraction of samples should be trimmed.
[12]:
corrupted_inds = np.random.randint(0, len(x_train), size=len(x_train) // 30)
x_train_corrupted = x_train.copy()
x_train_corrupted[corrupted_inds] += np.random.standard_normal((len(corrupted_inds), 3))
# Without trimming
sr3_optimizer = ps.SR3()
with ignore_specific_warnings():
model = ps.SINDy(optimizer=sr3_optimizer).fit(x_train_corrupted, t=dt)
print("Without trimming")
model.print()
# With trimming
sr3_optimizer = ps.SR3(trimming_fraction=0.1)
with ignore_specific_warnings():
model = ps.SINDy(optimizer=sr3_optimizer).fit(x_train_corrupted, t=dt)
print("\nWith trimming")
model.print()
Without trimming
(x0)' = -3.548 1 + -8.985 x0 + 9.327 x1 + 0.505 x2
(x1)' = -10.974 1 + 27.060 x0 + -0.581 x1 + 1.471 x2 + 0.228 x0^2 + -0.209 x0 x1 + -0.975 x0 x2
(x2)' = 2.165 1 + 0.846 x0 + -0.462 x1 + -3.002 x2 + 1.029 x0 x1
With trimming
(x0)' = -10.005 x0 + 10.003 x1
(x1)' = 27.990 x0 + -0.997 x1 + -1.000 x0 x2
(x2)' = -2.664 x2 + 0.999 x0 x1
SR3 regularizers
The default regularizer with SR3 is the L0 norm, but L1 and L2 are allowed. Note that the pure L2 option is notably less sparse than the other options.
[13]:
weight = ps.SR3.calculate_l0_weight(0.1, 1)
sr3_optimizer = ps.SR3(reg_weight_lam=weight, regularizer="l0")
with ignore_specific_warnings():
model = ps.SINDy(optimizer=sr3_optimizer).fit(x_train, t=dt)
print("L0 regularizer: ")
model.print()
sr3_optimizer = ps.SR3(reg_weight_lam=0.1, regularizer="l1")
with ignore_specific_warnings():
model = ps.SINDy(optimizer=sr3_optimizer).fit(x_train, t=dt)
print("L1 regularizer: ")
model.print()
sr3_optimizer = ps.SR3(reg_weight_lam=0.1, regularizer="l2")
with ignore_specific_warnings():
model = ps.SINDy(optimizer=sr3_optimizer).fit(x_train, t=dt)
print("L2 regularizer: ")
model.print()
L0 regularizer:
(x0)' = -10.005 x0 + 10.003 x1
(x1)' = 27.991 x0 + -0.998 x1 + -1.000 x0 x2
(x2)' = -2.666 x2 + 0.999 x0 x1
L1 regularizer:
(x0)' = -9.905 x0 + 9.903 x1
(x1)' = 27.891 x0 + -0.898 x1 + -0.900 x0 x2
(x2)' = -2.566 x2 + 0.899 x0 x1
L2 regularizer:
(x0)' = -0.002 1 + -8.336 x0 + 8.335 x1
(x1)' = -0.011 1 + 23.323 x0 + -0.830 x1 + 0.001 x2 + -0.833 x0 x2
(x2)' = 0.006 1 + 0.005 x0 + -0.003 x1 + -2.222 x2 + 0.001 x0^2 + 0.833 x0 x1
SR3 - with variable thresholding
SR3 and its variants (ConstrainedSR3, TrappingSR3, SINDyPI) can use a matrix of thresholds to set different thresholds for different terms.
[14]:
# Without thresholds matrix
weight = ps.SR3.calculate_l0_weight(0.1, 1)
sr3_optimizer = ps.SR3(reg_weight_lam=0.1, regularizer="l0")
print("Threshold = 0.1 for all terms")
model.print()
# With thresholds matrix
weights = 2 * np.ones((3, 10))
weights[4:, :] = ps.SR3.calculate_l0_weight(0.1, 1)
sr3_optimizer = ps.SR3(regularizer="weighted_l0", reg_weight_lam=weights)
model = ps.SINDy(optimizer=sr3_optimizer).fit(x_train, t=dt)
print("Threshold = 0.1 for quadratic terms, else threshold = 1")
model.print()
Threshold = 0.1 for all terms
(x0)' = -0.002 1 + -8.336 x0 + 8.335 x1
(x1)' = -0.011 1 + 23.323 x0 + -0.830 x1 + 0.001 x2 + -0.833 x0 x2
(x2)' = 0.006 1 + 0.005 x0 + -0.003 x1 + -2.222 x2 + 0.001 x0^2 + 0.833 x0 x1
Threshold = 0.1 for quadratic terms, else threshold = 1
(x0)' = -10.005 x0 + 10.003 x1
(x1)' = 27.990 x0
(x2)' = -2.666 x2
It can be seen that the x1 term in the second equation correctly gets truncated with these thresholds.
ConstrainedSR3
We can impose linear equality and inequality constraints on the coefficients in the SINDy model using the ConstrainedSR3 class. Below we constrain the x0 coefficient in the second equation to be exactly 28 and the x0 and x1 coefficients in the first equations to be negatives of one another. See this notebook for examples.
[15]:
# Figure out how many library features there will be
library = ps.PolynomialLibrary()
library.fit([ps.AxesArray(x_train, {"ax_sample": 0, "ax_coord": 1})])
n_features = library.n_output_features_
print(f"Features ({n_features}):", library.get_feature_names())
Features (10): ['1', 'x0', 'x1', 'x2', 'x0^2', 'x0 x1', 'x0 x2', 'x1^2', 'x1 x2', 'x2^2']
[16]:
# Set constraints
n_targets = x_train.shape[1]
constraint_rhs = np.array([0, 28])
# One row per constraint, one column per coefficient
constraint_lhs = np.zeros((2, n_targets * n_features))
# 1 * (x0 coefficient) + 1 * (x1 coefficient) = 0
constraint_lhs[0, 1] = 1
constraint_lhs[0, 2] = 1
# 1 * (x0 coefficient) = 28
constraint_lhs[1, 1 + n_features] = 1
optimizer = ps.ConstrainedSR3(
constraint_rhs=constraint_rhs, constraint_lhs=constraint_lhs
)
model = ps.SINDy(optimizer=optimizer, feature_library=library).fit(x_train, t=dt)
model.print()
(x0)' = -10.002 x0 + 10.002 x1
(x1)' = 28.000 x0 + -1.003 x1 + -1.000 x0 x2
(x2)' = -2.666 x2 + 0.999 x0 x1
/home/jake/github/pysindy/pysindy/optimizers/_constrained_sr3.py:151: UserWarning: constraint_lhs and constraint_rhs passed to the optimizer, but user did not specify if the constraints were equality or inequality constraints. Assuming equality constraints.
warnings.warn(
/home/jake/github/pysindy/pysindy/optimizers/_constrained_sr3.py:318: UserWarning: Target format constraints are deprecated.
self.constraint_lhs = reorder_constraints(self.constraint_lhs, n_features)
/home/jake/github/pysindy/pysindy/optimizers/_constrained_sr3.py:398: UserWarning: Target format constraints are deprecated.
self.constraint_lhs = reorder_constraints(
[17]:
weight = ps.ConstrainedSR3.calculate_l0_weight(10, 1)
# Try with normalize columns (doesn't work with constraints!!!)
optimizer = ps.ConstrainedSR3(
constraint_rhs=constraint_rhs,
constraint_lhs=constraint_lhs,
normalize_columns=True,
reg_weight_lam=weight,
)
with ignore_specific_warnings():
model = ps.SINDy(optimizer=optimizer, feature_library=library).fit(x_train, t=dt)
model.print()
(x0)' = -11.085 x0 + 9.701 x1 + 0.020 x2 + 0.021 x0 x2 + 0.025 x1 x2
(x1)' = 2.338 1 + 0.050 x0 + 10.311 x1 + 0.368 x2 + -0.047 x0^2 + 0.197 x0 x1 + -0.308 x0 x2 + -0.125 x1^2 + -0.183 x1 x2 + -0.006 x2^2
(x2)' = -2.666 x2 + 1.000 x0 x1
/home/jake/github/pysindy/pysindy/optimizers/_constrained_sr3.py:151: UserWarning: constraint_lhs and constraint_rhs passed to the optimizer, but user did not specify if the constraints were equality or inequality constraints. Assuming equality constraints.
warnings.warn(
[18]:
# Repeat with inequality constraints, need CVXPY installed
try:
import cvxpy # noqa: F401
run_cvxpy = True
except ImportError:
run_cvxpy = False
print("No CVXPY package is installed")
[19]:
if run_cvxpy:
# Repeat with inequality constraints
eps = 1e-5
constraint_rhs = np.array([eps, eps, 28])
# One row per constraint, one column per coefficient
constraint_lhs = np.zeros((3, n_targets * n_features))
# 1 * (x0 coefficient) + 1 * (x1 coefficient) <= eps
constraint_lhs[0, 1] = 1
constraint_lhs[0, 2] = 1
# -eps <= 1 * (x0 coefficient) + 1 * (x1 coefficient)
constraint_lhs[1, 1] = -1
constraint_lhs[1, 2] = -1
# 1 * (x0 coefficient) <= 28
constraint_lhs[2, 1 + n_features] = 1
optimizer = ps.ConstrainedSR3(
constraint_rhs=constraint_rhs,
constraint_lhs=constraint_lhs,
inequality_constraints=True,
regularizer="l1",
tol=1e-7,
reg_weight_lam=10,
max_iter=10000,
)
model = ps.SINDy(optimizer=optimizer, feature_library=library).fit(x_train, t=dt)
model.print()
print(optimizer.coef_[0, 1], optimizer.coef_[0, 2])
/home/jake/github/pysindy/pysindy/optimizers/_constrained_sr3.py:318: UserWarning: Target format constraints are deprecated.
self.constraint_lhs = reorder_constraints(self.constraint_lhs, n_features)
(x0)' = -10.000 x0 + 10.000 x1
(x1)' = 27.985 x0 + -0.994 x1 + -1.000 x0 x2
(x2)' = 0.001 x0 + -2.665 x2 + 0.001 x0^2 + 0.999 x0 x1
-10.000125514899203 10.000135502271625
/home/jake/github/pysindy/env/lib/python3.10/site-packages/cvxpy/problems/problem.py:1510: UserWarning: Solution may be inaccurate. Try another solver, adjusting the solver settings, or solve with verbose=True for more information.
warnings.warn(
/home/jake/github/pysindy/pysindy/optimizers/_constrained_sr3.py:398: UserWarning: Target format constraints are deprecated.
self.constraint_lhs = reorder_constraints(
MIOSR
Mixed-integer optimized sparse regression (MIOSR) is an optimizer which solves the NP-hard subset selection problem to provable optimality using techniques from mixed-integer optimization. This optimizer is expected to be most performant compared to heuristics in settings with limited data or on systems with small coefficients. See Bertsimas, Dimitris, and Wes Gurnee. “Learning Sparse Nonlinear Dynamics via Mixed-Integer Optimization.” arXiv preprint arXiv:2206.00176 (2022). for details.
Note, MIOSR requires gurobipy as a dependency. Please either pip install gurobipy or pip install pysindy[miosr].
Gurobi is a private company, but a limited academic license is available when you pip install. If you have previously installed gurobipy but your license has expired, import gurobipy will work but using the functionality will throw a GurobiError. See here for how to renew a free academic license.
[20]:
try:
import gurobipy
run_miosr = True
GurobiError = gurobipy.GurobiError
except ImportError:
run_miosr = False
MIOSR can handle sparsity constraints in two ways: dimensionwise sparsity where the algorithm is fit once per each dimension, and global sparsity, where all dimensions are fit jointly to respect the overall sparsity constraint. Additionally, MIOSR can handle constraints and can be adapted to implement custom constraints by advanced users.
MIOSR target_sparsity vs. group_sparsity
[21]:
if run_miosr:
try:
miosr_optimizer = ps.MIOSR(target_sparsity=7)
model = ps.SINDy(optimizer=miosr_optimizer)
model.fit(x_train, t=dt)
model.print()
except GurobiError:
print("User has an expired gurobi license")
Restricted license - for non-production use only - expires 2026-11-23
(x0)' = -9.999 x0 + 9.999 x1
(x1)' = 27.992 x0 + -0.999 x1 + -1.000 x0 x2
(x2)' = -2.666 x2 + 1.000 x0 x1
[22]:
if run_miosr:
try:
miosr_optimizer = ps.MIOSR(group_sparsity=(2, 3, 2), target_sparsity=None)
model = ps.SINDy(optimizer=miosr_optimizer)
model.fit(x_train, t=dt)
model.print()
except GurobiError:
print("User does not have a gurobi license")
(x0)' = -9.999 x0 + 9.999 x1
(x1)' = 27.992 x0 + -0.999 x1 + -1.000 x0 x2
(x2)' = -2.666 x2 + 1.000 x0 x1
MIOSR (verbose) with equality constraints
[23]:
if run_miosr:
try:
# Set constraints
n_targets = x_train.shape[1]
constraint_rhs = np.array([0, 28])
# One row per constraint, one column per coefficient
constraint_lhs = np.zeros((2, n_targets * n_features))
# 1 * (x0 coefficient) + 1 * (x1 coefficient) = 0
constraint_lhs[0, 1] = 1
constraint_lhs[0, 2] = 1
# 1 * (x0 coefficient) = 28
constraint_lhs[1, 1 + n_features] = 1
miosr_optimizer = ps.MIOSR(
constraint_rhs=constraint_rhs,
constraint_lhs=constraint_lhs,
verbose=True, # print the full gurobi log
target_sparsity=7,
)
model = ps.SINDy(optimizer=miosr_optimizer, feature_library=library)
model.fit(x_train, t=dt)
model.print()
print(optimizer.coef_[0, 1], optimizer.coef_[0, 2])
except GurobiError:
print("User does not have a gurobi license")
Set parameter OutputFlag to value 1
Set parameter TimeLimit to value 10
Gurobi Optimizer version 12.0.2 build v12.0.2rc0 (linux64 - "Ubuntu 22.04.5 LTS")
CPU model: Intel(R) Core(TM) i7-7500U CPU @ 2.70GHz, instruction set [SSE2|AVX|AVX2]
Thread count: 2 physical cores, 4 logical processors, using up to 4 threads
Non-default parameters:
TimeLimit 10
Optimize a model with 3 rows, 60 columns and 33 nonzeros
Model fingerprint: 0xe72a982a
Model has 165 quadratic objective terms
Model has 30 SOS constraints
Variable types: 30 continuous, 30 integer (30 binary)
Coefficient statistics:
Matrix range [1e+00, 1e+00]
Objective range [2e+02, 9e+07]
QObjective range [1e+04, 6e+09]
Bounds range [1e+00, 1e+00]
RHS range [2e+01, 3e+01]
Warning: Model contains large quadratic objective coefficients
Consider reformulating model or setting NumericFocus parameter
to avoid numerical issues.
Presolve removed 1 rows and 2 columns
Presolve time: 0.00s
Presolved: 2 rows, 58 columns, 31 nonzeros
Presolved model has 29 SOS constraint(s)
Presolved model has 155 quadratic objective terms
Variable types: 29 continuous, 29 integer (29 binary)
Found heuristic solution: objective 2.813404e+08
Root relaxation: objective -6.078269e+07, 78 iterations, 0.00 seconds (0.00 work units)
Nodes | Current Node | Objective Bounds | Work
Expl Unexpl | Obj Depth IntInf | Incumbent BestBd Gap | It/Node Time
0 0 -6.078e+07 0 21 2.8134e+08 -6.078e+07 122% - 0s
H 0 0 5.687556e+07 -6.078e+07 207% - 0s
0 0 -6.078e+07 0 21 5.6876e+07 -6.078e+07 207% - 0s
H 0 0 -6.07827e+07 -6.078e+07 0.00% - 0s
Explored 1 nodes (78 simplex iterations) in 0.03 seconds (0.00 work units)
Thread count was 4 (of 4 available processors)
Solution count 3: -6.07827e+07 5.68756e+07 2.8134e+08
Optimal solution found (tolerance 1.00e-04)
Best objective -6.078268757125e+07, best bound -6.078268817068e+07, gap 0.0000%
(x0)' = -9.999 x0 + 9.999 x1
(x1)' = 28.000 x0 + -1.001 x1 + -1.000 x0 x2
(x2)' = -2.666 x2 + 1.000 x0 x1
-10.000125514899203 10.000135502271625
See the gurobi documentation for more information on how to read the log output and this tutorial on the basics of mixed-integer optimization.
SSR (greedy algorithm)
Stepwise sparse regression (SSR) is a greedy algorithm which solves the problem (defaults to ridge regression) by iteratively truncating the smallest coefficient during the optimization. There are many ways one can decide to truncate terms. We implement two popular ways, truncating the smallest coefficient at each iteration, or chopping each coefficient, computing N - 1 models, and then choosing the model with the lowest residual error. See this notebook for examples.
[24]:
ssr_optimizer = ps.SSR(alpha=0.05)
model = ps.SINDy(optimizer=ssr_optimizer)
model.fit(x_train, t=dt)
model.print()
(x0)' = -9.999 x0 + 9.999 x1
(x1)' = 27.992 x0 + -0.999 x1 + -1.000 x0 x2
(x2)' = -2.666 x2 + 1.000 x0 x1
The alpha parameter is the same here as in the STLSQ optimizer. It determines the amount of L2 regularization to use, so if alpha is nonzero, this is doing Ridge regression rather than least-squares regression.
[25]:
ssr_optimizer = ps.SSR(alpha=0.05, criteria="model_residual")
model = ps.SINDy(optimizer=ssr_optimizer)
model.fit(x_train, t=dt)
model.print()
(x0)' = -9.999 x0 + 10.000 x1
(x1)' = 27.992 x0 + -0.999 x1 + -1.000 x0 x2
(x2)' = -2.667 x2 + 1.000 x0 x1
The kappa parameter determines how sparse a solution is desired.
[26]:
ssr_optimizer = ps.SSR(alpha=0.05, criteria="model_residual", kappa=1e-3)
model = ps.SINDy(optimizer=ssr_optimizer)
model.fit(x_train, t=dt)
model.print()
(x0)' = -9.999 x0 + 10.000 x1
(x1)' = 27.992 x0 + -0.999 x1 + -1.000 x0 x2
(x2)' = -2.667 x2 + 1.000 x0 x1
FROLS (greedy algorithm)
Forward Regression Orthogonal Least Squares (FROLS) is another greedy algorithm which solves the least-squares regression problem (actually default is to solve ridge regression) with \(L_0\) norm by iteratively selecting the most correlated function in the library. At each step, the candidate functions are orthogonalized with respect to the already-selected functions. The selection criteria is the Error Reduction Ratio, i.e. the normalized increase in the explained output variance due to the addition of a given function to the basis. See this notebook for examples.
[27]:
optimizer = ps.FROLS(alpha=0.05)
model = ps.SINDy(optimizer=optimizer)
model.fit(x_train, t=dt)
model.print()
(x0)' = -0.001 1 + -10.005 x0 + 10.003 x1
(x1)' = -0.005 1 + 27.990 x0 + -0.997 x1 + -1.000 x0 x2
(x2)' = 0.019 1 + -2.668 x2 + 0.999 x0 x1
The kappa parameter determines how sparse a solution is desired.
[28]:
optimizer = ps.FROLS(alpha=0.05, kappa=1e-7)
model = ps.SINDy(optimizer=optimizer)
model.fit(x_train, t=dt)
model.print()
(x0)' = -9.999 x0 + 9.999 x1
(x1)' = 27.992 x0 + -0.999 x1 + -1.000 x0 x2
(x2)' = -0.001 1 + -2.666 x2 + 1.000 x0 x1
LASSO
In this example we use a third-party Lasso implementation (from scikit-learn) as the optimizer.
[29]:
lasso_optimizer = Lasso(alpha=2, max_iter=2000, fit_intercept=False)
model = ps.SINDy(optimizer=lasso_optimizer)
model.fit(x_train, t=dt)
model.print()
(x0)' = -0.097 x0 + 3.789 x1 + 0.047 x0^2 + -0.080 x0 x1 + -0.275 x0 x2 + 0.036 x1^2 + 0.175 x1 x2 + -0.004 x2^2
(x1)' = 25.449 x0 + 0.224 x1 + -0.007 x0^2 + 0.012 x0 x1 + -0.932 x0 x2 + -0.005 x1^2 + -0.029 x1 x2 + 0.001 x2^2
(x2)' = -2.482 x2 + 0.048 x0^2 + 0.968 x0 x1 + -0.008 x2^2
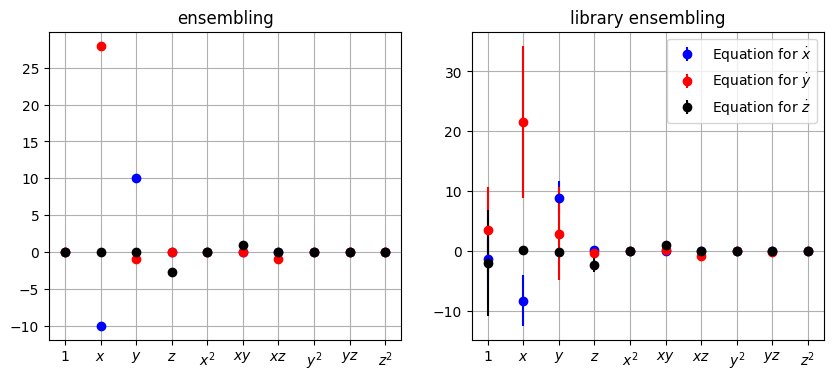
Ensemble methods
One way to improve SINDy performance is to generate many models by sub-sampling the time series (ensemble) or sub-sampling the candidate library \(\mathbf{\Theta}\) (library ensemble). The resulting models can then be synthesized by taking the average (bagging), taking the median (this is the recommended because it works well in practice), or some other post-processing. See this notebook for more examples.
[30]:
# Default is to sample the entire time series with replacement, generating 10 models on roughly
# 60% of the total data, with duplicates.
# Custom feature names
np.random.seed(100)
feature_names = ["x", "y", "z"]
ensemble_optimizer = ps.EnsembleOptimizer(
ps.STLSQ(threshold=1e-3, normalize_columns=False),
bagging=True,
n_subset=int(0.6 * x_train.shape[0]),
)
model = ps.SINDy(optimizer=ensemble_optimizer)
model.fit(x_train, t=dt, feature_names=feature_names)
ensemble_coefs = ensemble_optimizer.coef_list
mean_ensemble = np.mean(ensemble_coefs, axis=0)
std_ensemble = np.std(ensemble_coefs, axis=0)
# Now we sub-sample the library. The default is to omit a single library term.
library_ensemble_optimizer = ps.EnsembleOptimizer(
ps.STLSQ(threshold=1e-3, normalize_columns=False), library_ensemble=True
)
model = ps.SINDy(optimizer=library_ensemble_optimizer)
model.fit(x_train, t=dt, feature_names=feature_names)
library_ensemble_coefs = library_ensemble_optimizer.coef_list
mean_library_ensemble = np.mean(library_ensemble_coefs, axis=0)
std_library_ensemble = np.std(library_ensemble_coefs, axis=0)
# Plot results
xticknames = model.get_feature_names()
for i in range(10):
xticknames[i] = "$" + xticknames[i] + "$"
plt.figure(figsize=(10, 4))
colors = ["b", "r", "k"]
plt.subplot(1, 2, 1)
plt.title("ensembling")
for i in range(3):
plt.errorbar(
range(10),
mean_ensemble[i, :],
yerr=std_ensemble[i, :],
fmt="o",
color=colors[i],
label=r"Equation for $\dot{" + feature_names[i] + r"}$",
)
ax = plt.gca()
plt.grid(True)
ax.set_xticks(range(10))
ax.set_xticklabels(xticknames, verticalalignment="top")
plt.subplot(1, 2, 2)
plt.title("library ensembling")
for i in range(3):
plt.errorbar(
range(10),
mean_library_ensemble[i, :],
yerr=std_library_ensemble[i, :],
fmt="o",
color=colors[i],
label=r"Equation for $\dot{" + feature_names[i] + r"}$",
)
ax = plt.gca()
plt.grid(True)
plt.legend()
ax.set_xticks(range(10))
ax.set_xticklabels(xticknames, verticalalignment="top")
plt.show()
Differentiation options
Pass in pre-computed derivatives
Rather than using one of PySINDy’s built-in differentiators, you can compute numerical derivatives using a method of your choice then pass them directly to the fit method. This option also enables you to use derivative data obtained directly from experiments.
[31]:
x_dot_precomputed = ps.FiniteDifference()._differentiate(x_train, t_train)
model = ps.SINDy()
model.fit(x_train, t=t_train, x_dot=x_dot_precomputed)
model.print()
(x0)' = -9.999 x0 + 9.999 x1
(x1)' = 27.992 x0 + -0.999 x1 + -1.000 x0 x2
(x2)' = -2.666 x2 + 1.000 x0 x1
Drop end points from finite difference computation
Many methods of numerical differentiation exhibit poor performance near the endpoints of the data. The FiniteDifference and SmoothedFiniteDifference methods allow one to easily drop the endpoints for improved accuracy.
[32]:
fd_drop_endpoints = ps.FiniteDifference(drop_endpoints=True)
model = ps.SINDy(differentiation_method=fd_drop_endpoints)
model.fit(x_train, t=t_train)
model.print()
(x0)' = -9.999 x0 + 9.999 x1
(x1)' = 27.992 x0 + -0.998 x1 + -1.000 x0 x2
(x2)' = -2.666 x2 + 1.000 x0 x1
Differentiation along specific array axis
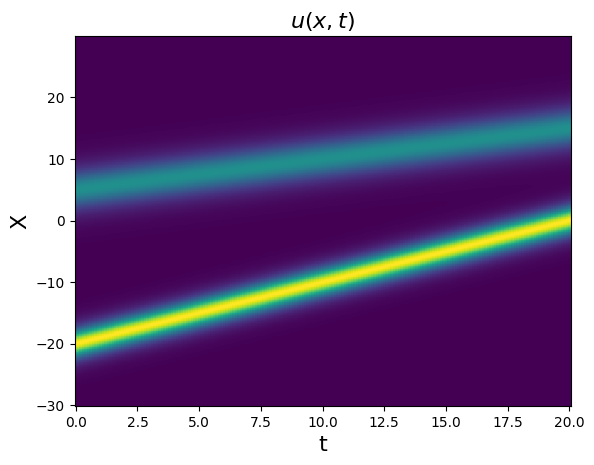
For partial differential equations (PDEs), you may have spatiotemporal data in a multi-dimensional array. For this case, the FiniteDifference method allows one to only differential along a specific axis, so one can easily differentiate in a specific spatial direction.
[33]:
from scipy.io import loadmat
# Load the data stored in a matlab .mat file
kdV = loadmat(data / "kdv.mat")
t = np.ravel(kdV["t"])
X = np.ravel(kdV["x"])
x = np.real(kdV["usol"])
dt_kdv = t[1] - t[0]
# Plot x and x_dot
plt.figure()
plt.pcolormesh(t, X, x)
plt.xlabel("t", fontsize=16)
plt.ylabel("X", fontsize=16)
plt.title(r"$u(x, t)$", fontsize=16)
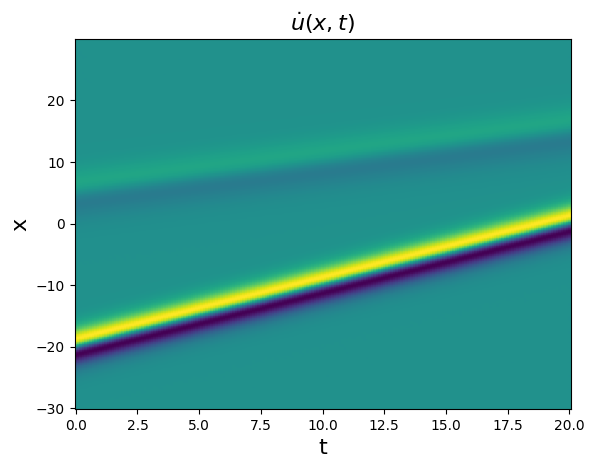
plt.figure()
x_dot = ps.FiniteDifference(axis=1)._differentiate(x, t=dt_kdv)
plt.pcolormesh(t, X, x_dot)
plt.xlabel("t", fontsize=16)
plt.ylabel("x", fontsize=16)
plt.title(r"$\dot{u}(x, t)$", fontsize=16)
plt.show()
Smoothed finite difference
This method, designed for noisy data, applies a smoother (the default is scipy.signal.savgol_filter) before performing differentiation.
[34]:
smoothed_fd = ps.SmoothedFiniteDifference()
model = ps.SINDy(differentiation_method=smoothed_fd)
model.fit(x_train, t=t_train)
model.print()
(x0)' = -9.999 x0 + 9.999 x1
(x1)' = 27.992 x0 + -0.999 x1 + -1.000 x0 x2
(x2)' = -2.666 x2 + 1.000 x0 x1
More differentiation options
PySINDy is compatible with any of the differentiation methods from the derivative package. They are explored in detail in this notebook.
PySINDy defines a SINDyDerivative class for interfacing with derivative methods. To use a differentiation method provided by derivative, simply pass into SINDyDerivative the keyword arguments you would give the dxdt method.
[35]:
spline_derivative = ps.SINDyDerivative(kind="spline", s=1e-2)
model = ps.SINDy(differentiation_method=spline_derivative)
model.fit(x_train, t=t_train)
model.print()
(x0)' = -10.000 x0 + 10.000 x1
(x1)' = 28.003 x0 + -1.001 x1 + -1.000 x0 x2
(x2)' = -2.667 x2 + 1.000 x0 x1
Feature libraries
Custom feature names
[36]:
feature_names = ["x", "y", "z"]
model = ps.SINDy()
model.fit(x_train, t=dt, feature_names=feature_names)
model.print()
(x)' = -9.999 x + 9.999 y
(y)' = 27.992 x + -0.999 y + -1.000 x z
(z)' = -2.666 z + 1.000 x y
Custom left-hand side when printing the model
[37]:
model = ps.SINDy()
model.fit(x_train, t=dt)
model.print(lhs=["dx0/dt", "dx1/dt", "dx2/dt"])
dx0/dt = -9.999 x0 + 9.999 x1
dx1/dt = 27.992 x0 + -0.999 x1 + -1.000 x0 x2
dx2/dt = -2.666 x2 + 1.000 x0 x1
Customize polynomial library
Omit interaction terms between variables, such as \(x_0 x_1\).
[38]:
poly_library = ps.PolynomialLibrary(include_interaction=False)
model = ps.SINDy(feature_library=poly_library, optimizer=ps.STLSQ(threshold=0.5))
model.fit(x_train, t=dt)
model.print()
(x0)' = -9.999 x0 + 9.999 x1
(x1)' = -12.142 x0 + 9.349 x1
(x2)' = 85.861 1 + 0.567 x0 + -7.354 x2 + 1.366 x0^2
Fourier library
[39]:
fourier_library = ps.FourierLibrary(n_frequencies=3)
model = ps.SINDy(feature_library=fourier_library, optimizer=ps.STLSQ(threshold=4))
model.fit(x_train, t=dt)
model.print()
(x0)' = 6.201 cos(1 x1)
(x1)' = -4.233 cos(1 x0) + -4.817 sin(1 x2) + 7.787 cos(1 x2) + -5.604 cos(2 x0) + 4.630 cos(3 x0) + 4.569 sin(3 x2)
(x2)' = 4.982 sin(1 x0) + 4.768 sin(1 x1) + -13.709 cos(2 x1) + 4.674 sin(3 x1) + -8.713 cos(3 x1)
Fully custom library
The CustomLibrary class gives you the option to pass in function names to improve the readability of the printed model. Each function “name” should itself be a function.
[40]:
library_functions = [
lambda x: np.exp(x),
lambda x: 1.0 / x,
lambda x: x,
lambda x, y: np.sin(x + y),
]
library_function_names = [
lambda x: "exp(" + x + ")",
lambda x: "1/" + x,
lambda x: x,
lambda x, y: "sin(" + x + "," + y + ")",
]
custom_library = ps.CustomLibrary(
library_functions=library_functions, function_names=library_function_names
)
model = ps.SINDy(feature_library=custom_library)
with ignore_specific_warnings():
model.fit(x_train, t=dt)
model.print()
(x0)' = -9.999 x0 + 9.999 x1
(x1)' = 1.197 1/x0 + -50.011 1/x2 + -12.462 x0 + 9.291 x1 + 0.383 x2 + 0.882 sin(x0,x1) + 1.984 sin(x0,x2) + -0.464 sin(x1,x2)
(x2)' = 0.874 1/x0 + -8.545 1/x2 + 0.114 x0 + 0.147 x1 + 3.659 sin(x0,x1) + -3.302 sin(x0,x2) + -3.094 sin(x1,x2)
Fully custom library, default function names
If no function names are given, default ones are given: f0, f1, …
[41]:
library_functions = [
lambda x: np.exp(x),
lambda x: 1.0 / x,
lambda x: x,
lambda x, y: np.sin(x + y),
]
custom_library = ps.CustomLibrary(library_functions=library_functions)
model = ps.SINDy(feature_library=custom_library)
with ignore_specific_warnings():
model.fit(x_train, t=dt)
model.print()
(x0)' = -9.999 f2(x0) + 9.999 f2(x1)
(x1)' = 1.197 f1(x0) + -50.011 f1(x2) + -12.462 f2(x0) + 9.291 f2(x1) + 0.383 f2(x2) + 0.882 f3(x0,x1) + 1.984 f3(x0,x2) + -0.464 f3(x1,x2)
(x2)' = 0.874 f1(x0) + -8.545 f1(x2) + 0.114 f2(x0) + 0.147 f2(x1) + 3.659 f3(x0,x1) + -3.302 f3(x0,x2) + -3.094 f3(x1,x2)
Identity library
The IdentityLibrary leaves input data untouched. It allows the flexibility for users to apply custom transformations to the input data before feeding it into a SINDy model.
[42]:
identity_library = ps.IdentityLibrary()
model = ps.SINDy(feature_library=identity_library)
model.fit(x_train, t=dt)
model.print()
(x0)' = -9.999 x0 + 9.999 x1
(x1)' = -12.450 x0 + 9.314 x1 + 0.299 x2
(x2)' = 0.257 x0
Concatenate two libraries
Two or more libraries can be combined via the + operator.
[43]:
identity_library = ps.IdentityLibrary()
fourier_library = ps.FourierLibrary()
combined_library = identity_library + fourier_library
model = ps.SINDy(feature_library=combined_library)
model.fit(x_train, t=dt, feature_names=feature_names)
model.print()
model.get_feature_names()
(x)' = -9.999 x + 9.999 y
(y)' = -12.512 x + 9.391 y + 0.302 z + -2.969 sin(1 x) + -3.341 cos(1 x) + -1.027 sin(1 y) + -6.675 cos(1 y) + -1.752 sin(1 z) + 3.392 cos(1 z)
(z)' = 0.120 x + 0.140 y + 5.950 sin(1 x) + 2.661 cos(1 x) + 7.917 sin(1 y) + -4.030 cos(1 y) + -1.238 sin(1 z) + -0.280 cos(1 z)
[43]:
['x',
'y',
'z',
'sin(1 x)',
'cos(1 x)',
'sin(1 y)',
'cos(1 y)',
'sin(1 z)',
'cos(1 z)']
Tensor two libraries together
Two or more libraries can be tensored together via the * operator.
[44]:
identity_library = ps.PolynomialLibrary(include_bias=False)
fourier_library = ps.FourierLibrary()
combined_library = identity_library * fourier_library
model = ps.SINDy(feature_library=combined_library)
model.fit(x_train, t=dt, feature_names=feature_names)
# model.print() # prints out long and unobvious model
print("Feature names:\n", model.get_feature_names())
Feature names:
['x sin(1 x)', 'x cos(1 x)', 'x sin(1 y)', 'x cos(1 y)', 'x sin(1 z)', 'x cos(1 z)', 'y sin(1 x)', 'y cos(1 x)', 'y sin(1 y)', 'y cos(1 y)', 'y sin(1 z)', 'y cos(1 z)', 'z sin(1 x)', 'z cos(1 x)', 'z sin(1 y)', 'z cos(1 y)', 'z sin(1 z)', 'z cos(1 z)', 'x^2 sin(1 x)', 'x^2 cos(1 x)', 'x^2 sin(1 y)', 'x^2 cos(1 y)', 'x^2 sin(1 z)', 'x^2 cos(1 z)', 'x y sin(1 x)', 'x y cos(1 x)', 'x y sin(1 y)', 'x y cos(1 y)', 'x y sin(1 z)', 'x y cos(1 z)', 'x z sin(1 x)', 'x z cos(1 x)', 'x z sin(1 y)', 'x z cos(1 y)', 'x z sin(1 z)', 'x z cos(1 z)', 'y^2 sin(1 x)', 'y^2 cos(1 x)', 'y^2 sin(1 y)', 'y^2 cos(1 y)', 'y^2 sin(1 z)', 'y^2 cos(1 z)', 'y z sin(1 x)', 'y z cos(1 x)', 'y z sin(1 y)', 'y z cos(1 y)', 'y z sin(1 z)', 'y z cos(1 z)', 'z^2 sin(1 x)', 'z^2 cos(1 x)', 'z^2 sin(1 y)', 'z^2 cos(1 y)', 'z^2 sin(1 z)', 'z^2 cos(1 z)']
[45]:
# the model prediction is quite bad of course
# because the library has mostly useless terms
x_dot_test_predicted = model.predict(x_test)
# Compute derivatives with a finite difference method, for comparison
x_dot_test_computed = model.differentiation_method(x_test, t=dt)
fig, axs = plt.subplots(x_test.shape[1], 1, sharex=True, figsize=(7, 9))
for i in range(x_test.shape[1]):
axs[i].plot(t_test, x_dot_test_computed[:, i], "k", label="numerical derivative")
axs[i].plot(t_test, x_dot_test_predicted[:, i], "r--", label="model prediction")
axs[i].legend()
axs[i].set(xlabel="t", ylabel=r"$\dot x_{}$".format(i))
fig.show()
/tmp/ipykernel_167005/2318777190.py:14: UserWarning: FigureCanvasAgg is non-interactive, and thus cannot be shown
fig.show()
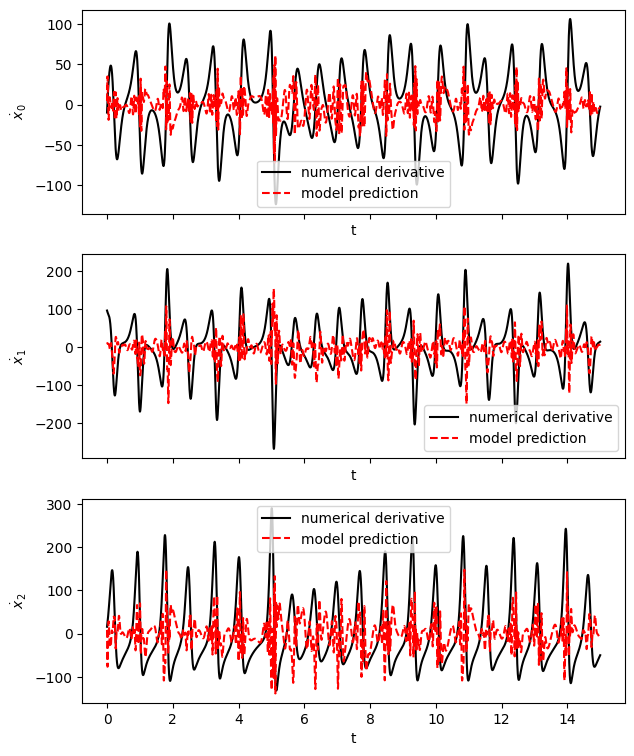
Generalized library
Create the most general and flexible possible library by combining and tensoring as many libraries as you want, and you can even specify which input variables to use to generate each library! A much more advanced example is shown further below for PDEs. One can specify:
N different libraries to add together
A list of inputs to use for each library. For two libraries with four inputs this would look like inputs_per_library = [[0, 1, 2, 3], [0, 1, 2, 3]] and to avoid using the first two input variables in the second library, you would change it to inputs_per_library = [[0, 1, 2, 3], [2, 3]].
A list of libraries to tensor together and add to the overall library. For four libraries, we could make three tensor libraries by using tensor_array = [[1, 0, 1, 1], [1, 1, 1, 1], [0, 0, 1, 1]]. The first sub-array takes the tensor product of libraries 0, 2, 3, the second takes the tensor product of all of them, and the last takes the tensor product of the libraries 2 and 3. This is a silly example since the [1, 1, 1, 1] tensor product already contains all the possible terms.
A list of library indices to exclude from the overall library. The first N libraries correspond to the input libraries and the subsequent indices correspond to the tensored libraries. For two libraries, exclude_libraries=[0,1] and tensor_array=[[1,1]] would result in a library consisting of only the tensor product. Note that using this is a more advanced feature, but with the benefit that it allows any SINDy library you want.
[46]:
# Initialize two libraries
poly_library = ps.PolynomialLibrary(include_bias=False)
fourier_library = ps.FourierLibrary()
# Initialize the default inputs, but
# don't use the x0 input for generating the Fourier library
inputs_per_library = [(0, 1, 2), (1, 2)]
# Tensor all the polynomial and Fourier library terms together
tensor_array = [[1, 1]]
# Initialize this generalized library, all the work hidden from the user!
generalized_library = ps.GeneralizedLibrary(
[poly_library, fourier_library],
tensor_array=tensor_array,
exclude_libraries=[1],
inputs_per_library=inputs_per_library,
)
# Fit the model and print the library feature names to check success
model = ps.SINDy(feature_library=generalized_library)
model.fit(x_train, t=dt, feature_names=feature_names)
model.print()
print("Feature names:\n", model.get_feature_names())
(x)' = -9.999 x + 9.999 y
(y)' = 27.992 x + -0.999 y + -1.000 x z
(z)' = -2.666 z + 1.000 x y
Feature names:
['x', 'y', 'z', 'x^2', 'x y', 'x z', 'y^2', 'y z', 'z^2', 'x sin(1 y)', 'x cos(1 y)', 'x sin(1 z)', 'x cos(1 z)', 'y sin(1 y)', 'y cos(1 y)', 'y sin(1 z)', 'y cos(1 z)', 'z sin(1 y)', 'z cos(1 y)', 'z sin(1 z)', 'z cos(1 z)', 'x^2 sin(1 y)', 'x^2 cos(1 y)', 'x^2 sin(1 z)', 'x^2 cos(1 z)', 'x y sin(1 y)', 'x y cos(1 y)', 'x y sin(1 z)', 'x y cos(1 z)', 'x z sin(1 y)', 'x z cos(1 y)', 'x z sin(1 z)', 'x z cos(1 z)', 'y^2 sin(1 y)', 'y^2 cos(1 y)', 'y^2 sin(1 z)', 'y^2 cos(1 z)', 'y z sin(1 y)', 'y z cos(1 y)', 'y z sin(1 z)', 'y z cos(1 z)', 'z^2 sin(1 y)', 'z^2 cos(1 y)', 'z^2 sin(1 z)', 'z^2 cos(1 z)']
SINDy with control (SINDYc)
SINDy models with control inputs can also be learned. Here we learn a Lorenz control model:
Train the model
[47]:
# Control input
def u_fun(t):
return np.column_stack([np.sin(2 * t), t**2])
# Generate measurement data
dt = 0.002
t_train = np.arange(0, t_end_train, dt)
t_train_span = (t_train[0], t_train[-1])
x0_train = [-8, 8, 27]
x_train = solve_ivp(
lorenz_control,
t_train_span,
x0_train,
t_eval=t_train,
args=(u_fun,),
**integrator_keywords,
).y.T
u_train = u_fun(t_train)
[48]:
# Instantiate and fit the SINDYc model
model = ps.SINDy()
model.fit(x_train, u=u_train, t=dt)
model.print()
(x0)' = -9.999 x0 + 9.999 x1 + 0.999 u0
(x1)' = 27.988 x0 + -0.998 x1 + -1.000 x0 x2
(x2)' = -2.666 x2 + -1.000 u1 + 1.000 x0 x1
Assess results on a test trajectory
[49]:
# Evolve the Lorenz equations in time using a different initial condition
t_test = np.arange(0, t_end_test, dt)
t_test_span = (t_test[0], t_test[-1])
u_test = u_fun(t_test)
x0_test = np.array([8, 7, 15])
x_test = solve_ivp(
lorenz_control,
t_test_span,
x0_test,
t_eval=t_test,
args=(u_fun,),
**integrator_keywords,
).y.T
u_test = u_fun(t_test)
# Compare SINDy-predicted derivatives with finite difference derivatives
print("Model score: %f" % model.score(x_test, u=u_test, t=dt))
Model score: 1.000000
Predict derivatives with learned model
[50]:
# Predict derivatives using the learned model
x_dot_test_predicted = model.predict(x_test, u=u_test)
# Compute derivatives with a finite difference method, for comparison
x_dot_test_computed = model.differentiation_method(x_test, t=dt)
fig, axs = plt.subplots(x_test.shape[1], 1, sharex=True, figsize=(7, 9))
for i in range(x_test.shape[1]):
axs[i].plot(t_test, x_dot_test_computed[:, i], "k", label="numerical derivative")
axs[i].plot(t_test, x_dot_test_predicted[:, i], "r--", label="model prediction")
axs[i].legend()
axs[i].set(xlabel="t", ylabel=r"$\dot x_{}$".format(i))
fig.show()
/tmp/ipykernel_167005/3279140504.py:13: UserWarning: FigureCanvasAgg is non-interactive, and thus cannot be shown
fig.show()
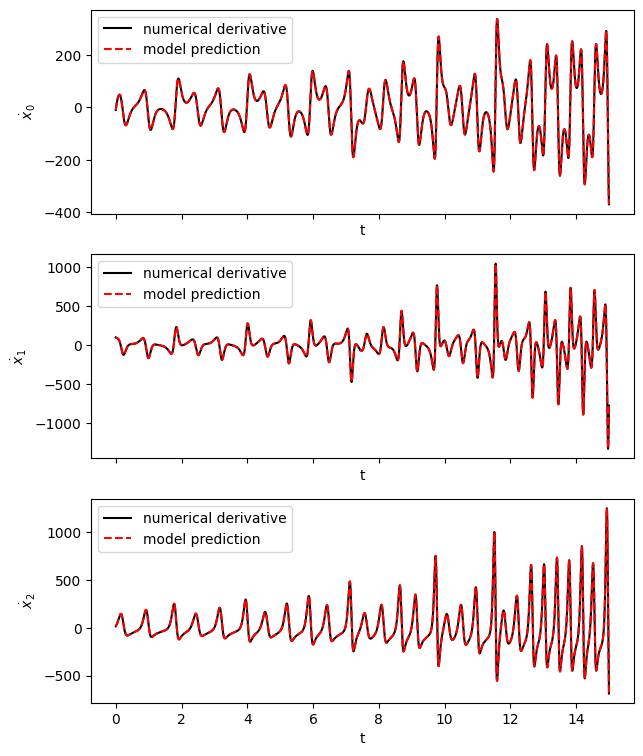
Simulate forward in time (control input function known)
When working with control inputs SINDy.simulate requires a function to be passed in for the control inputs, u, because the default integrator used in SINDy.simulate uses adaptive time-stepping. We show what to do in the case when you do not know the functional form for the control inputs in the example following this one.
[51]:
# Evolve the new initial condition in time with the SINDy model
x_test_sim = model.simulate(x0_test, t_test, u=u_fun)
fig, axs = plt.subplots(x_test.shape[1], 1, sharex=True, figsize=(7, 9))
for i in range(x_test.shape[1]):
axs[i].plot(t_test, x_test[:, i], "k", label="true simulation")
axs[i].plot(t_test, x_test_sim[:, i], "r--", label="model simulation")
axs[i].legend()
axs[i].set(xlabel="t", ylabel="$x_{}$".format(i))
fig = plt.figure(figsize=(10, 4.5))
ax1 = fig.add_subplot(121, projection="3d")
ax1.plot(x_test[:, 0], x_test[:, 1], x_test[:, 2], "k")
ax1.set(xlabel="$x_0$", ylabel="$x_1$", zlabel="$x_2$", title="true simulation")
ax2 = fig.add_subplot(122, projection="3d")
ax2.plot(x_test_sim[:, 0], x_test_sim[:, 1], x_test_sim[:, 2], "r--")
ax2.set(xlabel="$x_0$", ylabel="$x_1$", zlabel="$x_2$", title="model simulation")
fig.show()
/tmp/ipykernel_167005/85401031.py:20: UserWarning: FigureCanvasAgg is non-interactive, and thus cannot be shown
fig.show()
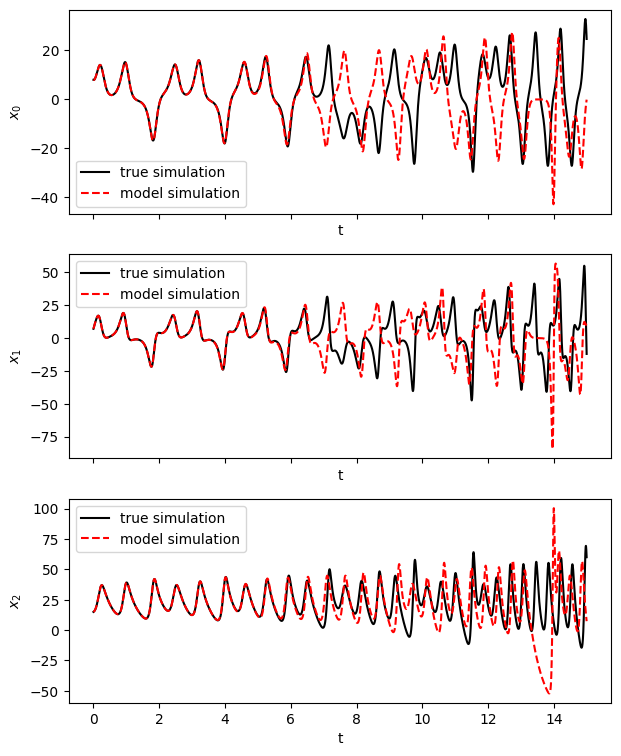
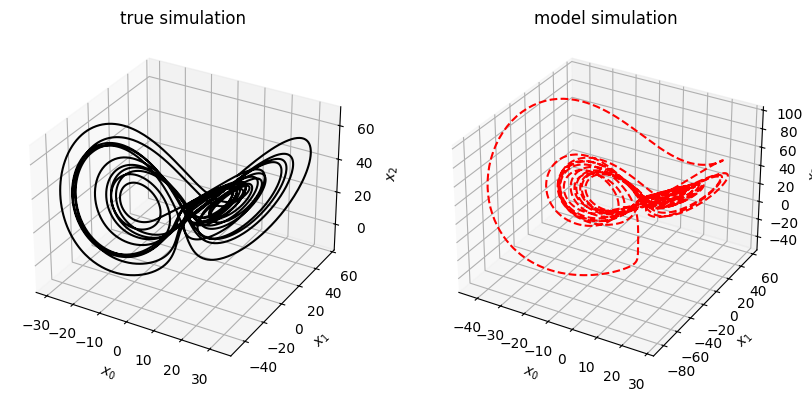
Simulate forward in time (unknown control input function)
If you only have a vector of control input values at the times in t_test and do not know the functional form for u, the simulate function will internally form an interpolating function based on the vector of control inputs. As a consequence of this interpolation procedure, simulate will not give a state estimate for the last time point in t_test. This is because the default integrator, scipy.integrate.solve_ivp (with LSODA as the default solver), is adaptive and sometimes
attempts to evaluate the interpolant outside the domain of interpolation, causing an error.
[52]:
u_test = u_fun(t_test)
[53]:
x_test_sim = model.simulate(x0_test, t_test, u=u_test)
# Note that the output is one example short of the length of t_test
print("Length of t_test:", len(t_test))
print("Length of simulation:", len(x_test_sim))
fig, axs = plt.subplots(x_test.shape[1], 1, sharex=True, figsize=(12, 4))
for i in range(x_test.shape[1]):
axs[i].plot(t_test[:-1], x_test[:-1, i], "k", label="true simulation")
axs[i].plot(t_test[:-1], x_test_sim[:, i], "r--", label="model simulation")
axs[i].set(xlabel="t", ylabel="$x_{}$".format(i))
fig.show()
/home/jake/github/pysindy/pysindy/_core.py:623: UserWarning: Last time point dropped in simulation because interpolation of control input was used. To avoid this, pass in a callable for u.
warnings.warn(
Length of t_test: 7500
Length of simulation: 7499
/tmp/ipykernel_167005/3503062763.py:13: UserWarning: FigureCanvasAgg is non-interactive, and thus cannot be shown
fig.show()
Implicit ODEs
How would we use SINDy to solve an implicit ODE? In other words, now the LHS can depend on x and x_dot,
In order to deal with this, we need a library \(\Theta(\mathbf{x}, \dot{\mathbf{x}})\). SINDy parallel implicit (SINDy-PI) is geared to solve these problems. It solves the optimization problem,
such that diag\((\mathbf{\Xi}) = 0\). So for every candidate library term it generates a different model. With N state variables, we need to choose N of the equations to solve for the system evolution. See the SINDy-PI notebook for more details.
Here we illustrate successful identification of the 1D Michelson-Menten enzyme model
Or, equivalently
Note that some of the model fits fail. This is usually because the LHS term being fitted is a poor match to the data, but this error can also be caused by CVXPY not liking the parameters passed to the solver.
[54]:
if run_cvxpy:
# define parameters
r = 1
dt = 0.001
if __name__ != "testing":
T = 4
else:
T = 0.02
t = np.arange(0, T + dt, dt)
t_span = (t[0], t[-1])
x0_train = [0.55]
x_train = solve_ivp(enzyme, t_span, x0_train, t_eval=t, **integrator_keywords).y.T
# Initialize custom SINDy library so that we can have
# x_dot inside it.
x_library_functions = [
lambda x: x,
lambda x, y: x * y,
lambda x: x**2,
lambda x, y, z: x * y * z,
lambda x, y: x * y**2,
lambda x: x**3,
lambda x, y, z, w: x * y * z * w,
lambda x, y, z: x * y * z**2,
lambda x, y: x * y**3,
lambda x: x**4,
]
x_dot_library_functions = [lambda x: x]
# library function names includes both the x_library_functions
# and x_dot_library_functions names
library_function_names = [
lambda x: x,
lambda x, y: x + y,
lambda x: x + x,
lambda x, y, z: x + y + z,
lambda x, y: x + y + y,
lambda x: x + x + x,
lambda x, y, z, w: x + y + z + w,
lambda x, y, z: x + y + z + z,
lambda x, y: x + y + y + y,
lambda x: x + x + x + x,
lambda x: x,
]
# Need to pass time base to the library so can build the x_dot library from x
sindy_library = ps.SINDyPILibrary(
library_functions=x_library_functions,
x_dot_library_functions=x_dot_library_functions,
t=t,
function_names=library_function_names,
include_bias=True,
)
# Use the SINDy-PI optimizer, which relies on CVXPY.
# Note that if LHS of the equation fits the data poorly,
# CVXPY often returns failure.
sindy_opt = ps.SINDyPI(
reg_weight_lam=1e-6,
tol=1e-8,
regularizer="l1",
max_iter=20000,
)
model = ps.SINDy(
optimizer=sindy_opt,
feature_library=sindy_library,
differentiation_method=ps.FiniteDifference(drop_endpoints=True),
)
model.fit(x_train, t=t)
model.print()
/home/jake/github/pysindy/pysindy/feature_library/sindy_pi_library.py:146: UserWarning: This library is deprecated in PySINDy versions > 1.7. Please use the PDE or WeakPDE libraries instead.
warnings.warn(
Model 0
Model 1
Model 2
Model 3
Model 4
Model 5
Model 6
Model 7
Model 8
Model 9
(1) = 5.000 x0 + 1.667 x0_dot + 5.556 x0x0_dot
(x0) = 0.200 1 + -0.333 x0_dot + -1.111 x0x0_dot
(x0x0) = 0.198 x0 + 0.007 x0x0x0 + -0.338 x0x0_dot + -1.099 x0x0x0_dot
(x0x0x0) = 0.007 1 + 0.419 x0x0x0x0 + -0.021 x0_dot + -0.922 x0x0x0_dot + -0.153 x0x0x0x0_dot
(x0x0x0x0) = -0.001 1 + 0.363 x0x0x0 + 0.041 x0x0_dot + -1.205 x0x0x0x0x0_dot
(x0_dot) = 0.600 1 + -3.000 x0 + -3.333 x0x0_dot
(x0x0_dot) = 0.180 1 + -0.900 x0 + -0.300 x0_dot
(x0x0x0_dot) = -0.004 1 + 0.136 x0 + -0.508 x0x0 + -0.344 x0x0x0 + -0.102 x0x0_dot + -0.219 x0x0x0x0x0_dot
(x0x0x0x0_dot) = 0.003 1 + 0.001 x0 + -0.391 x0x0x0 + -0.247 x0x0x0x0 + -0.108 x0x0_dot
(x0x0x0x0x0_dot) = 0.001 1 + -0.670 x0x0x0x0 + -0.005 x0_dot + 0.029 x0x0_dot + -0.271 x0x0x0_dot
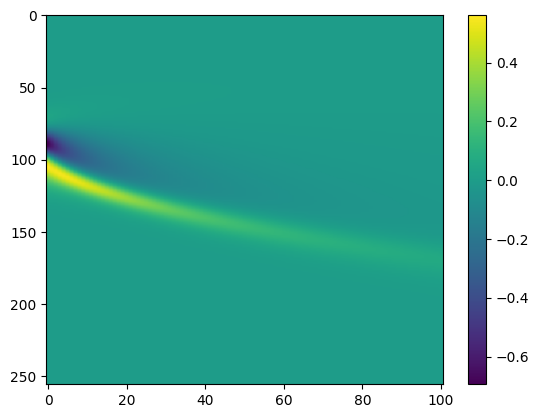
PDEFIND Feature Overview
PySINDy now supports SINDy for PDE identification (PDE-FIND) (Rudy, Samuel H., Steven L. Brunton, Joshua L. Proctor, and J. Nathan Kutz. “Data-driven discovery of partial differential equations.” Science Advances 3, no. 4 (2017): e1602614.). We illustrate a basic example on Burgers’ equation:
Note that for noisy PDE data, the most robust method is to use the weak form of PDEFIND (see below)!
[55]:
# Load data
data = loadmat(data / "burgers.mat")
t = np.ravel(data["t"])
x = np.ravel(data["x"])
u = np.real(data["usol"])
dt = t[1] - t[0]
dx = x[1] - x[0]
u_dot = ps.FiniteDifference(axis=-1)._differentiate(u, t=dt)
# Plot the spatiotemporal data
plt.figure()
plt.imshow(u, aspect="auto")
plt.colorbar()
plt.figure()
plt.imshow(u_dot, aspect="auto")
plt.colorbar()
u = np.reshape(u, (len(x), len(t), 1))
# Define quadratic library with up to third order derivatives
# on a uniform spatial grid. Do not include a constant term in the function_library!
pde_lib = ps.PDELibrary(
function_library=ps.PolynomialLibrary(degree=2, include_bias=False),
derivative_order=3,
spatial_grid=x,
diff_kwargs={"is_uniform": True, "periodic": True},
)
optimizer = ps.STLSQ(threshold=0.1, alpha=1e-5, normalize_columns=True)
model = ps.SINDy(feature_library=pde_lib, optimizer=optimizer)
# Note that the dimensions of u are reshaped internally,
# according to the dimensions in spatial_grid
model.fit(u, t=dt)
model.print()
(x0)' = 0.100 x0_11 + -1.001 x0x0_1

Weak formulation system identification improves robustness to noise.
PySINDy also supports weak form PDE identification following Reinbold et al. (2019).
[56]:
# Same library but using the weak formulation
X, T = np.meshgrid(x, t)
XT = np.array([X, T]).T
pde_lib = ps.WeakPDELibrary(
function_library=ps.PolynomialLibrary(degree=2, include_bias=False),
derivative_order=3,
spatiotemporal_grid=XT,
is_uniform=True,
)
/home/jake/github/pysindy/pysindy/feature_library/weak_pde_library.py:177: UserWarning: is_uniform and periodic have been deprecated.in favor of differetiation_method and diff_kwargs.
warnings.warn(
[57]:
optimizer = ps.STLSQ(threshold=0.01, alpha=1e-5, normalize_columns=True)
model = ps.SINDy(feature_library=pde_lib, optimizer=optimizer)
# Note that reshaping u is done internally
model.fit(u, t=dt)
model.print()
(x0)' = 0.101 x0_11 + -1.003 x0x0_1
GeneralizedLibrary
The GeneralizedLibrary is meant for identifying ODEs/PDEs the depend on the spatial and/or temporal coordinates and/or nonlinear functions of derivative terms.
Often, especially for PDEs, there is some explicit spatiotemporal dependence such as through an external potential. For instance, a well known PDE is the Poisson equation for the electric potential in 2D:
Note that all other SINDy libraries implemented in PySINDy only allow for functions of :math:`phi(x, y)` on the RHS of the SINDy equation. This method allows for functions of the spatial and temporal coordinates like \(\rho(x, y)\), as well as anything else you can imagine.
Let’s suppose we have a distribution like the following
We can actually directly input \((\partial_{xx} + \partial_{yy})\phi(x, y)\) as “x_dot” in the SINDy fit, functionally replacing the normal left-hand-side (LHS) of the SINDy equation. Then we can build a candidate library of terms to discover the correct charge density matching this data.
In the following, we will build three different libraries, each using their own subset of inputs, tensor a subset of them together, and fit a model. This is total overkill for this problem but hopefully is illustrative.
[58]:
# Define the spatial grid
if __name__ != "testing":
nx = 50
ny = 100
else:
nx = 6 # must be even
ny = 10
Lx = 1
Ly = 1
x = np.linspace(0, Lx, nx)
dx = x[1] - x[0]
y = np.linspace(0, Ly, ny)
dy = y[1] - y[0]
X, Y = np.meshgrid(x, y, indexing="ij")
# Define rho
rho = X**2 + Y**2
plt.figure(figsize=(20, 3))
plt.subplot(1, 5, 1)
plt.imshow(rho, aspect="auto", origin="lower")
plt.title(r"$\rho(x, y)$")
plt.colorbar()
# Generate the PDE data for phi by fourier transforms
# since this is homogeneous PDE
# and we assume periodic boundary conditions
nx2 = int(nx / 2)
ny2 = int(ny / 2)
# Define Fourier wavevectors (kx, ky)
kx = (2 * np.pi / Lx) * np.hstack(
(np.linspace(0, nx2 - 1, nx2), np.linspace(-nx2, -1, nx2))
)
ky = (2 * np.pi / Ly) * np.hstack(
(np.linspace(0, ny2 - 1, ny2), np.linspace(-ny2, -1, ny2))
)
# Get 2D mesh in (kx, ky)
KX, KY = np.meshgrid(kx, ky, indexing="ij")
K2 = KX**2 + KY**2
K2[0, 0] = 1e-5
# Generate phi data by solving the PDE and plot results
phi = np.real(np.fft.ifft2(-np.fft.fft2(rho) / K2))
plt.subplot(1, 5, 2)
plt.imshow(phi, aspect="auto", origin="lower")
plt.title(r"$\phi(x, y)$")
plt.colorbar()
# Make del^2 phi and plot various quantities
phi_xx = ps.FiniteDifference(d=2, axis=0)._differentiate(phi, dx)
phi_yy = ps.FiniteDifference(d=2, axis=1)._differentiate(phi, dy)
plt.subplot(1, 5, 3)
plt.imshow(phi_xx, aspect="auto", origin="lower")
plt.title(r"$\phi_{xx}(x, y)$")
plt.subplot(1, 5, 4)
plt.imshow(phi_yy, aspect="auto", origin="lower")
plt.title(r"$\phi_{yy}(x, y)$")
plt.subplot(1, 5, 5)
plt.imshow(
phi_xx + phi_yy + abs(np.min(phi_xx + phi_yy)),
aspect="auto",
origin="lower",
)
plt.title(r"$\phi_{xx}(x, y) + \phi_{yy}(x, y)$")
plt.colorbar()
# Define a PolynomialLibrary, FourierLibrary, and PDELibrary
poly_library = ps.PolynomialLibrary(include_bias=False)
fourier_library = ps.FourierLibrary()
X_mesh, Y_mesh = np.meshgrid(x, y)
pde_library = ps.PDELibrary(
function_library=ps.CustomLibrary(library_functions=[], function_names=[]),
derivative_order=1,
spatial_grid=np.asarray([X_mesh, Y_mesh]).T,
)
# Inputs are going to be all the variables [phi, X, Y].
# Remember we can use a subset of these input variables to generate each library
data = np.transpose(np.asarray([phi, X, Y]), [1, 2, 0])
# The 'x_dot' terms will be [phi_xx, X, Y]
# Remember these are the things that are being fit in the SINDy regression
Laplacian_phi = phi_xx + phi_yy + abs(np.min(phi_xx + phi_yy))
data_dot = np.transpose(np.asarray([Laplacian_phi, X, Y]), [1, 2, 0])
# Tensor polynomial library with the PDE library
tensor_array = [[1, 0, 1]]
# Remove X and Y from PDE library terms because why would we take these derivatives
inputs_per_library = [(0, 1, 2), (0, 1, 2), (0,)]
# Fit a generalized library of 3 feature libraries + 1 internally
# generated tensored library and only use the input variable phi
# for the PDELibrary. Note that this holds true both for the
# individual PDELibrary and any tensored libraries constructed from it.
generalized_library = ps.GeneralizedLibrary(
[poly_library, fourier_library, pde_library],
tensor_array=tensor_array,
inputs_per_library=inputs_per_library,
)
optimizer = ps.STLSQ(threshold=8, alpha=1e-3, normalize_columns=True)
model = ps.SINDy(feature_library=generalized_library, optimizer=optimizer)
model.fit(data, x_dot=data_dot, t=1)
# Note scale of phi is large so some coefficients >> 1
# --> would want to rescale phi with eps_0 for a harder problem
model.print()
(x0)' = 1.045 x1^2 + 1.061 x2^2
(x1)' = 1.000 x1
(x2)' = 1.000 x2

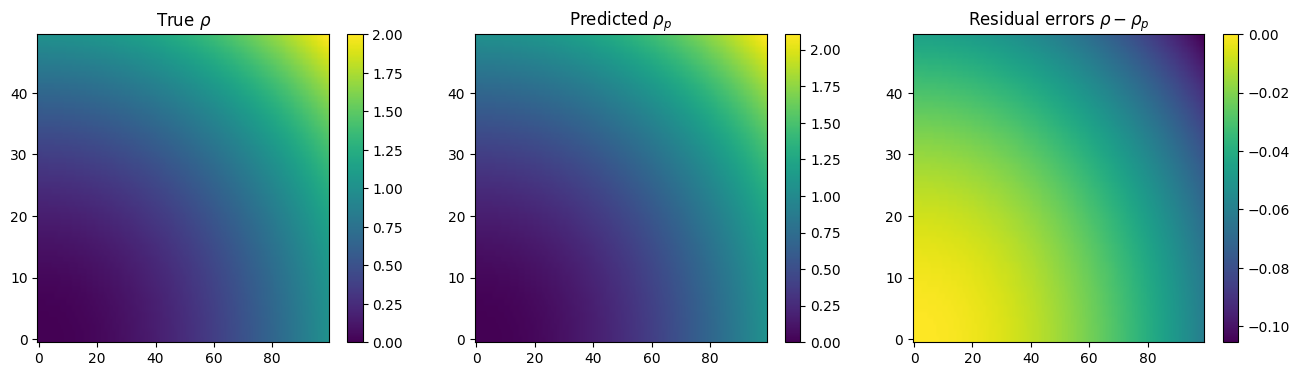
[59]:
# Get prediction of rho and plot results
# predict expects a time axis...so add one and ignore it...
data_shaped = data.reshape((data.shape[0], data.shape[1], 1, data.shape[2]))
rho_pred = model.predict(data_shaped)[:, :, 0, :]
if __name__ != "testing":
plt.figure(figsize=(16, 4))
plt.subplot(1, 3, 1)
plt.title(r"True $\rho$")
plt.imshow(rho, aspect="auto", origin="lower")
plt.colorbar()
plt.subplot(1, 3, 2)
plt.title(r"Predicted $\rho_p$")
plt.imshow(rho_pred[:, :, 0], aspect="auto", origin="lower")
plt.colorbar()
plt.subplot(1, 3, 3)
plt.title(r"Residual errors $\rho - \rho_p$")
plt.imshow(rho - rho_pred[:, :, 0], aspect="auto", origin="lower")
plt.colorbar()
print("Feature names:\n", model.get_feature_names())
Feature names:
['x0', 'x1', 'x2', 'x0^2', 'x0 x1', 'x0 x2', 'x1^2', 'x1 x2', 'x2^2', 'sin(1 x0)', 'cos(1 x0)', 'sin(1 x1)', 'cos(1 x1)', 'sin(1 x2)', 'cos(1 x2)', 'x0_2', 'x0_1', 'x0 x0_2', 'x0 x0_1', 'x1 x0_2', 'x1 x0_1', 'x2 x0_2', 'x2 x0_1', 'x0^2 x0_2', 'x0^2 x0_1', 'x0 x1 x0_2', 'x0 x1 x0_1', 'x0 x2 x0_2', 'x0 x2 x0_1', 'x1^2 x0_2', 'x1^2 x0_1', 'x1 x2 x0_2', 'x1 x2 x0_1', 'x2^2 x0_2', 'x2^2 x0_1']
[ ]: