pysindy.DiscreteSINDy
- class pysindy.DiscreteSINDy(optimizer: BaseOptimizer | None = None, feature_library: BaseFeatureLibrary | None = None)[source]
Sparse Identification of Nonlinear Dynamical Systems (SINDy) for discrete time systems.
- Parameters:
optimizer (optimizer object, optional) – Optimization method used to fit the SINDy model. This must be a class extending
pysindy.optimizers.BaseOptimizer. The default isSTLSQ.feature_library (feature library object, optional) – Feature library object used to specify candidate right-hand side features. This must be a class extending
pysindy.feature_library.base.BaseFeatureLibrary. The default option isPolynomialLibrary.
- Attributes:
model (
sklearn.multioutput.MultiOutputRegressorobject) – The fitted SINDy model.n_input_features_ (int) – The total number of input features.
n_output_features_ (int) – The total number of output features. This number is a function of
self.n_input_featuresand the feature library being used.n_control_features_ (int) – The total number of control input features.
Examples
>>> import numpy as np >>> import pysindy as ps >>> import matplotlib.pyplot as plt >>> def f(x): >>> return 3.6 * x * (1 - x) >>> n_steps = 20 >>> eps = 0.001 >>> x_map = np.zeros((n_steps)) >>> x_map[0] = 0.5 >>> for i in range(1, n_steps): >>> x_map[i] = f(x_map[i - 1]) + eps * np.random.randn() >>> x_train_map = x_map[:16] >>> x_test_map = x_map[16:] >>> model = ps.DiscreteSINDy() >>> model.fit(x_train_map, t=1) >>> model.print() (x0)[k+1] = 0.006 1 + 3.581 x0[k] + -3.586 x0[k]^2 >>> model.coefficients() >>> model.predict(x_test_map) AxesArray([[0.8268863 ], [0.51884209], [0.89919392], [0.33532148]]) >>> model.score(x_test_map, t=1) 0.9998547755296847 >>> model.simulate(x0=0.5, t=20) array([[0.5 ], [0.90037072], [0.32376537], [0.78980964], [0.59788467], [0.86556721], [0.41950949], [0.877508 ], [0.38763939], [0.85561537], [0.44528986], [0.88988815], [0.35351698], [0.8241012 ], [0.52224203], [0.89849516], [0.32914646], [0.79648209], [0.58382694], [0.87479097]])
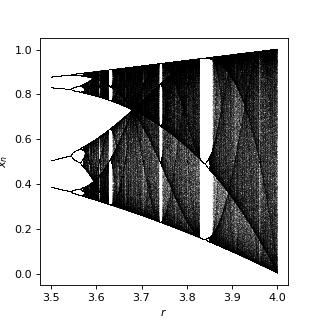
num = 1000 N = 1000 N_drop = 500 r0 = 3.5 rs = r0 + np.arange(num) / num * (4 - r0) xss = [] for r in rs: xs = [] x = 0.5 for n in range(N + N_drop): if n >= N_drop: xs = xs + [x] x = r * x * (1 - x) xss = xss + [xs] plt.figure(figsize=(4, 4), dpi=100) for ind in range(num): plt.plot( np.ones(N) * rs[ind], xss[ind], ",", alpha=0.1, c="black", rasterized=True ) plt.xlabel("$r$") plt.ylabel("$x_n$") plt.show()
>>> rs_train = [3.6, 3.7, 3.8, 3.9] >>> xs_train = [np.array(xss[np.where(np.array(rs) == r)[0][0]]) for r in rs_train] >>> feature_lib = ps.PolynomialLibrary(degree=3, include_bias=True) >>> parameter_lib = ps.PolynomialLibrary(degree=1, include_bias=True) >>> lib = ps.ParameterizedLibrary( >>> feature_library=feature_lib, >>> parameter_library=parameter_lib, >>> num_features=1, >>> num_parameters=1, >>> ) >>> opt = ps.STLSQ(threshold=1e-1, normalize_columns=False) >>> model = ps.DiscreteSINDy(feature_library=lib, optimizer=opt) >>> model.fit(xs_train, u=rs_train, t=1, feature_names=["x", "r"]) >>> model.print() (x)[k+1] = 1.000 r[k] x[k] + -1.000 r[k] x[k]^2
Methods
Get the right hand sides of the DiscreteSINDy model equations.
Fit a DiscreteSINDy model.
Print the DiscreteSINDy model equations.
Returns a score for the next state prediction produced by the model.
Configure whether metadata should be requested to be passed to the
fitmethod.Configure whether metadata should be requested to be passed to the
predictmethod.Configure whether metadata should be requested to be passed to the
scoremethod.Simulate the DiscreteSINDy model forward in time.
Attributes
feature_libraryoptimizerfeature_names- equations(precision: int = 3) list[str][source]
Get the right hand sides of the DiscreteSINDy model equations.
- Parameters:
precision (int, optional (default 3)) – Number of decimal points to include for each coefficient in the equation.
- Returns:
equations – List of strings representing the DiscreteSINDy model equations for each input feature.
- Return type:
list of strings
- fit(x, t, x_next=None, u=None, feature_names: list[str] | None = None, sample_weight: TrajectoryType | None = None)[source]
Fit a DiscreteSINDy model.
- Parameters:
x (array-like or list of array-like, shape (n_samples, n_input_features)) – Training data of the current state of the system. If training data contains multiple trajectories, x should be a list containing data for each trajectory. Individual trajectories may contain different numbers of samples.
t (float, numpy array of shape (n_samples,), or list of numpy arrays) – If t is a float, it specifies the timestep between each sample. If array-like, it specifies the time at which each sample was collected. In this case the values in t must be strictly increasing. In the case of multi-trajectory training data, t may also be a list of arrays containing the collection times for each individual trajectory.
x_next (array-like or list of array-like, shape (n_samples, n_input_features), optional (default None)) – Optional data of the system forwarded by one time step. If not provided, the next will be computed by taking the training data by one time step. If x_next is provided, it must match the shape of the training data and these values will be used as the next state.
u (array-like or list of array-like, shape (n_samples, n_control_features), optional (default None)) – Control variables/inputs. Include this variable to use sparse identification for nonlinear dynamical systems for control (SINDYc). If training data contains multiple trajectories (i.e. if x is a list of array-like), then u should be a list containing control variable data for each trajectory. Individual trajectories may contain different numbers of samples.
feature_names (list of string, length n_input_features, optional) – Names for the input features (e.g.
['x', 'y', 'z']). If None, will use['x0', 'x1', ...].sample_weight (list of array-like) – Each entry must match the spatial/time shape of the corresponding trajectory (same axes as
xwith the coordinate axis collapsed to length 1). Automatic broadcasting is not applied. Weights to give to the samples to give more importance to less noisy or more informative samples.
- Returns:
self
- Return type:
a fitted
DiscreteSINDyinstance
- print(precision=3, **kwargs)[source]
Print the DiscreteSINDy model equations.
- Parameters:
precision (int, optional (default 3)) – Precision to be used when printing out model coefficients.
**kwargs (Additional keyword arguments passed to the builtin print function)
- score(x, t, u=None, x_next=None, metric=<function r2_score>, sample_weight: ~pysindy._core.TrajectoryType | None = None, **metric_kws)[source]
Returns a score for the next state prediction produced by the model.
- Parameters:
x (array-like or list of array-like, shape (n_samples, n_input_features)) – Samples from which to make predictions.
t (float, numpy array of shape (n_samples,), or list of numpy arrays) – Time step between samples or array of collection times. Optional, used to compute the time derivatives of the samples if x_dot is not provided.
u (array-like or list of array-like, shape(n_samples, n_control_features), optional (default None)) – Control variables. If
multiple_trajectories==Truethen u must be a list of control variable data from each trajectory. If the model was fit with control variables then u is not optional.metric (callable, optional) – Metric function with which to score the prediction. Default is the R^2 coefficient of determination. See Scikit-learn for more options.
sample_weight (list of array-like) – Each entry must match the spatial/time shape of the corresponding trajectory (same axes as
xwith the coordinate axis collapsed to length 1). Automatic broadcasting is not applied. Weights to give to the samples to give more importance to less noisy or more informative samples.metric_kws (dict, optional) – Optional keyword arguments to pass to the metric function.
- Returns:
score – Metric function value for the model prediction of x_next.
- Return type:
float
- set_fit_request(*, feature_names: bool | None | str = '$UNCHANGED$', sample_weight: bool | None | str = '$UNCHANGED$', t: bool | None | str = '$UNCHANGED$', u: bool | None | str = '$UNCHANGED$', x: bool | None | str = '$UNCHANGED$', x_next: bool | None | str = '$UNCHANGED$') DiscreteSINDy
Configure whether metadata should be requested to be passed to the
fitmethod.Note that this method is only relevant when this estimator is used as a sub-estimator within a meta-estimator and metadata routing is enabled with
enable_metadata_routing=True(seesklearn.set_config). Please check the User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed tofitif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it tofit.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
- Parameters:
feature_names (str, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED) – Metadata routing for
feature_namesparameter infit.sample_weight (str, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED) – Metadata routing for
sample_weightparameter infit.t (str, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED) – Metadata routing for
tparameter infit.u (str, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED) – Metadata routing for
uparameter infit.x (str, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED) – Metadata routing for
xparameter infit.x_next (str, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED) – Metadata routing for
x_nextparameter infit.
- Returns:
self – The updated object.
- Return type:
object
- set_predict_request(*, u: bool | None | str = '$UNCHANGED$', x: bool | None | str = '$UNCHANGED$') DiscreteSINDy
Configure whether metadata should be requested to be passed to the
predictmethod.Note that this method is only relevant when this estimator is used as a sub-estimator within a meta-estimator and metadata routing is enabled with
enable_metadata_routing=True(seesklearn.set_config). Please check the User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed topredictif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it topredict.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
- Parameters:
u (str, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED) – Metadata routing for
uparameter inpredict.x (str, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED) – Metadata routing for
xparameter inpredict.
- Returns:
self – The updated object.
- Return type:
object
- set_score_request(*, metric: bool | None | str = '$UNCHANGED$', sample_weight: bool | None | str = '$UNCHANGED$', t: bool | None | str = '$UNCHANGED$', u: bool | None | str = '$UNCHANGED$', x: bool | None | str = '$UNCHANGED$', x_next: bool | None | str = '$UNCHANGED$') DiscreteSINDy
Configure whether metadata should be requested to be passed to the
scoremethod.Note that this method is only relevant when this estimator is used as a sub-estimator within a meta-estimator and metadata routing is enabled with
enable_metadata_routing=True(seesklearn.set_config). Please check the User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed toscoreif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it toscore.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
- Parameters:
metric (str, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED) – Metadata routing for
metricparameter inscore.sample_weight (str, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED) – Metadata routing for
sample_weightparameter inscore.t (str, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED) – Metadata routing for
tparameter inscore.u (str, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED) – Metadata routing for
uparameter inscore.x (str, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED) – Metadata routing for
xparameter inscore.x_next (str, True, False, or None, default=sklearn.utils.metadata_routing.UNCHANGED) – Metadata routing for
x_nextparameter inscore.
- Returns:
self – The updated object.
- Return type:
object
- simulate(x0, t, u=None, stop_condition=None)[source]
Simulate the DiscreteSINDy model forward in time.
- Parameters:
x0 (numpy array, size [n_features]) – Initial condition from which to simulate.
t (int) – Number of time steps to predict.
u (list/array, optional (default None)) – Control inputs. A list (with
len(u) == t) or array (withu.shape[0] == 1) giving the control inputs at each step.stop_condition (function object, optional) – If model is in discrete time, optional function that gives a stopping condition for stepping the simulation forward.
- Returns:
x – Simulation results
- Return type:
numpy array, shape (n_samples, n_features)