Trapping SINDy
By Alan Kaptanoglu and Jared Callaham
A very common issue is that models identified by system identification methods typically have no guarantees that the models are numerically or physically stable. This can be addressed with heuristic, data-driven, or analytic closure models, but we have recently directly promoted globally stable models into the system identification itself. This is really nice but two caveats, (1) the regression is nonconvex and there a number of hyperparameters, so this method can be difficult to learn, and (2) in order to promote global stability, one needs an analytic result from stability theory, and the one we use applies only for fluid and plasma flows with energy-preserving, quadratic, nonlinearities. This energy-preserving structure is quite common for fluid flows.
This example illustrates the use of a new “trapping SINDy” extension on a number of canonical fluid systems. The algorithm searches for globally stable systems with energy-preserving quadratic nonlinearities. The full description can be found in our recent paper: Kaptanoglu, Alan A., et al. “Promoting global stability in data-driven models of quadratic nonlinear dynamics.” Physical Review Fluids 6.9 (2021): 094401. This builds off of the new constrained SINDy algorithm based on SR3. The trapping theorem for stability utilized in this SINDy algorithm can be found in Schlegel, M., & Noack, B. R. (2015). On long-term boundedness of Galerkin models. Journal of Fluid Mechanics, 765, 325-352.
Note, important fix made in latest PySINDy version for systems with dimension > 3 for stability promotion.
Note, most of these examples are run at lower resolution than in the paper, so that the notebook executes much faster.
![]()
[1]:
# Import libraries
import warnings
import numpy as np
import scipy.io as sio
from matplotlib import pyplot as plt
from scipy.integrate import solve_ivp
import pysindy as ps
from pysindy.utils import burgers_galerkin
from pysindy.utils import lorenz
from pysindy.utils import meanfield
from pysindy.utils import mhd
from pysindy.utils import oscillator
# ignore user warnings
warnings.filterwarnings("ignore")
rng = np.random.default_rng(1)
The trapping algorithm only applies to fluid and plasma flows with energy-preserving, quadratic nonlinear structure, so we need to explicitly constrain the coefficients to conform to this structure. Below we import some utility functions that pre-calculate the things we need.
[2]:
from trapping_utils import (
integrator_keywords,
sindy_library,
sindy_library_no_bias,
make_fits,
make_lissajou,
check_local_stability,
trapping_region,
make_progress_plots,
galerkin_model,
obj_function,
)
Mean field model
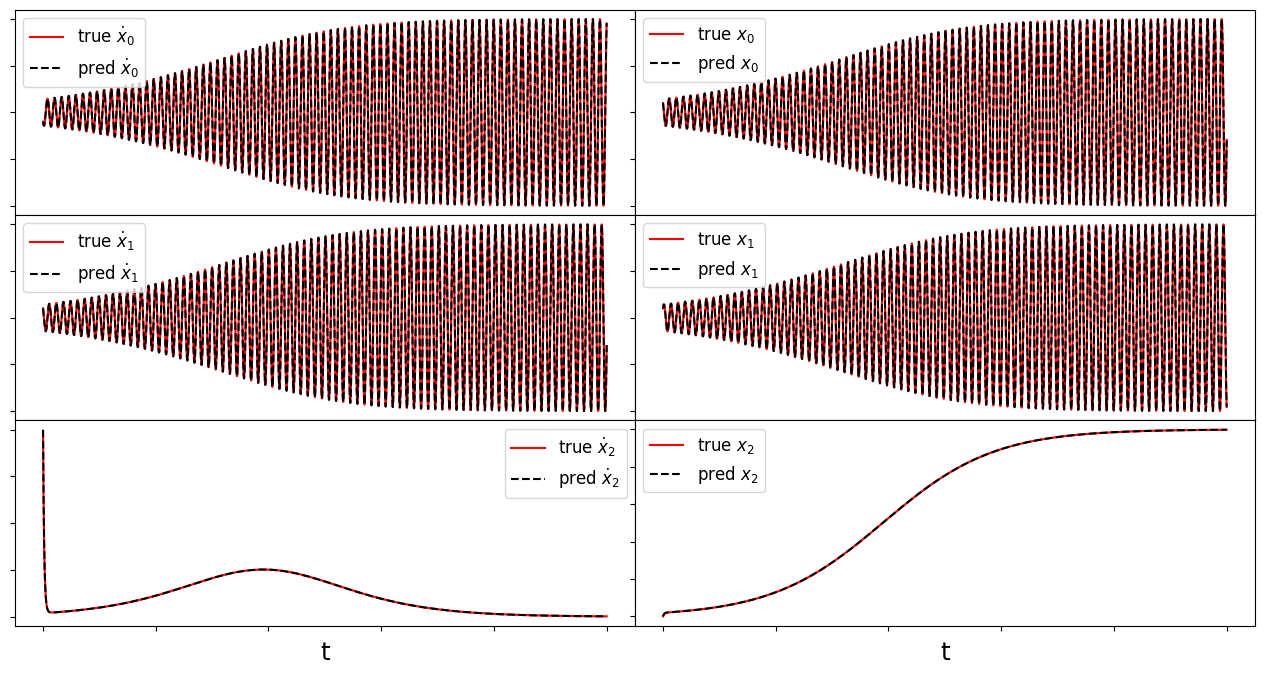
Often the trajectories of nonlinear dynamical systems whose linear parts have some stable directions will approach slow manifolds of reduced dimension with respect to the full state space. As an example of this behavior, consider the following linear-quadratic system originally proposed by Noack et al. (2003) as a simplified model of the von Karman vortex shedding problem:
where \(\mathbf{L}\) and \(\mathbf{Q}\) denote the linear and quadratic parts of the model, respectively.
Systems of this form commonly arise in PDEs with a pair of unstable eigenmodes represented by \(x\) and \(y\). The third variable \(z\) models the effects of mean-field deformations due to nonlinear self-interactions of the instability modes. The linear component is the generic linear part of a system undergoing a supercritical Hopf bifurcation at \(\mu = 0\); for \(\mu \ll 1\) trajectories quickly approach the parabolic manifold defined by \(z = x^2 + y^2\). All solutions asymptotically approach a stable limit cycle on which \(z = x^2 + y^2 = \mu\). It can be shown that \(\mathbf{m} = [0, 0, \mu+\epsilon]\), \(\epsilon > 0\) produces a negative definite matrix defined through
where \(\mathbf{L}^S = \mathbf{L} + \mathbf{L}^T\) is the symmetrized linear part of the model. From the Schlegel and Noack trapping theorem (and our trapping SINDy paper), this negative definite matrix allows us to conclude that this system exhibits a trapping region. We can show this analytically, and illustrate below our algorithm can discover it.
[3]:
# define parameters
r = 3
mu = 1e-2
dt = 0.01
T = 500
t = np.arange(0, T + dt, dt)
t_span = (t[0], t[-1])
x0 = rng.random((3,)) - 0.5
x_train = solve_ivp(
meanfield, t_span, x0, t_eval=t, args=(mu,), **integrator_keywords
).y.T
x0 = (mu, mu, 0)
x_test = solve_ivp(
meanfield, t_span, x0, t_eval=t, args=(mu,), **integrator_keywords
).y.T
# define hyperparameters
reg_weight_lam = 0.0
eta = 1e5
max_iter = 5000
# run trapping SINDy algorithm
sindy_opt = ps.TrappingSR3(
_n_tgts=3,
_include_bias=True,
reg_weight_lam=reg_weight_lam,
eta=eta,
max_iter=max_iter,
gamma=-1,
verbose=True,
)
model = ps.SINDy(
optimizer=sindy_opt,
feature_library=sindy_library,
differentiation_method=ps.FiniteDifference(drop_endpoints=True),
)
model.fit(x_train, t=t)
model.print()
Xi = model.coefficients().T
xdot_test = model.differentiate(x_test, t=t)
xdot_test_pred = model.predict(x_test)
x_train_pred = model.simulate(x_train[0, :], t, integrator_kws=integrator_keywords)
x_test_pred = model.simulate(x_test[0, :], t, integrator_kws=integrator_keywords)
# plotting and analysis
make_fits(r, t, xdot_test, xdot_test_pred, x_test, x_test_pred, "meanfield")
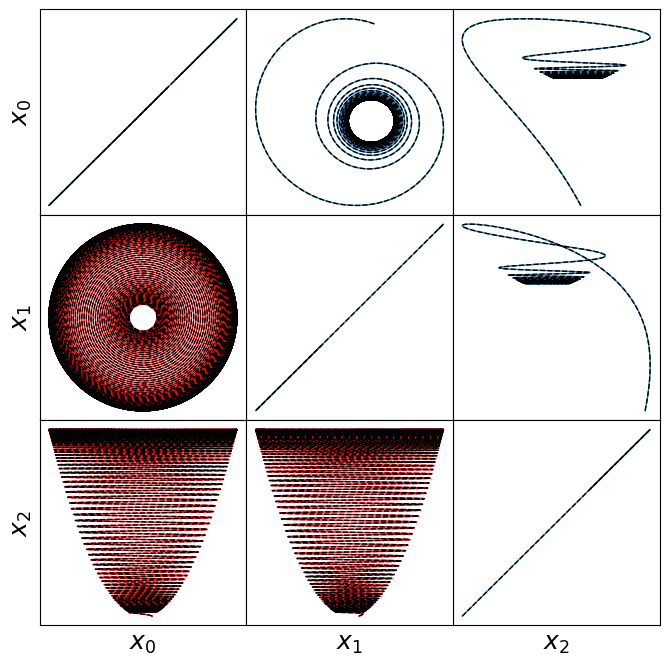
make_lissajou(r, x_train, x_test, x_train_pred, x_test_pred, "meanfield")
E_pred = np.linalg.norm(x_test - x_test_pred) / np.linalg.norm(x_test)
print("Frobenius Error = ", E_pred)
mean_val = np.mean(x_test_pred, axis=0)
mean_val = np.sqrt(np.sum(mean_val**2))
check_local_stability(Xi, sindy_opt, mean_val)
# compute relative Frobenius error in the model coefficients
terms = sindy_library.get_feature_names()
Xi_meanfield = np.zeros(Xi.shape)
Xi_meanfield[1 : r + 1, :] = np.asarray([[0.01, -1, 0], [1, 0.01, 0], [0, 0, -1]]).T
Xi_meanfield[terms.index("x0 x2"), 0] = -1
Xi_meanfield[terms.index("x1 x2"), 1] = -1
Xi_meanfield[terms.index("x0^2"), 2] = 1
Xi_meanfield[terms.index("x1^2"), 2] = 1
coef_pred = np.linalg.norm(Xi_meanfield - Xi) / np.linalg.norm(Xi_meanfield)
print("Frobenius coefficient error = ", coef_pred)
# Compute time-averaged dX/dt error
deriv_error = np.zeros(xdot_test.shape[0])
for i in range(xdot_test.shape[0]):
deriv_error[i] = np.dot(
xdot_test[i, :] - xdot_test_pred[i, :], xdot_test[i, :] - xdot_test_pred[i, :]
) / np.dot(xdot_test[i, :], xdot_test[i, :])
print("Time-averaged derivative error = ", np.nanmean(deriv_error))
Iter ... |y-Xw|^2 ... |Pw-A|^2/eta ... |w|_1 ... |Qijk|/a ... |Qijk+...|/b ... Total:
0 ... 5.203e-09 ... 9.468e-05 ... 0.00e+00 ... 1.50e-20 ... 1.54e-48 ... 9.47e-05
500 ... 4.015e-09 ... 3.025e-07 ... 0.00e+00 ... 1.50e-20 ... 4.31e-49 ... 3.07e-07
1000 ... 4.015e-09 ... 5.788e-08 ... 0.00e+00 ... 1.50e-20 ... 1.65e-48 ... 6.19e-08
1500 ... 4.015e-09 ... 2.077e-08 ... 0.00e+00 ... 1.50e-20 ... 2.51e-48 ... 2.48e-08
2000 ... 4.015e-09 ... 1.013e-08 ... 0.00e+00 ... 1.50e-20 ... 9.80e-49 ... 1.41e-08
2500 ... 4.015e-09 ... 5.867e-09 ... 0.00e+00 ... 1.50e-20 ... 2.76e-48 ... 9.88e-09
3000 ... 4.015e-09 ... 3.786e-09 ... 0.00e+00 ... 1.50e-20 ... 3.08e-49 ... 7.80e-09
3500 ... 4.015e-09 ... 2.630e-09 ... 0.00e+00 ... 1.50e-20 ... 1.08e-48 ... 6.64e-09
4000 ... 4.015e-09 ... 1.927e-09 ... 0.00e+00 ... 1.50e-20 ... 1.59e-48 ... 5.94e-09
4500 ... 4.015e-09 ... 1.468e-09 ... 0.00e+00 ... 1.50e-20 ... 4.36e-49 ... 5.48e-09
(x0)' = 0.010 x0 + -1.000 x1 + -1.000 x0 x2
(x1)' = 1.000 x0 + 0.010 x1 + -1.000 x1 x2
(x2)' = -1.000 x2 + 1.000 x0^2 + 1.000 x1^2
Frobenius Error = 0.005915059546690636
optimal m: [-0.1254261 -0.06016724 1.31318278]
As eigvals: [-1.31837551 -1.30318407 -0.98480456]
0.5 * |tilde{H}_0|_F = 1.4938306382013248e-14
0.5 * |tilde{H}_0|_F^2 / beta = 4.463059951257955e-48
Estimate of trapping region size, Rm = 1.22071489987813
Normalized trapping region size, Reff = 200.285704898953
Local stability size, R_ls= 98887169889671.1
Frobenius coefficient error = 1.9181496031000266e-05
Time-averaged derivative error = 6.066077925488403e-12
Atmospheric oscillator model
Here we briefly look at a more complicated Lorenz-like system of coupled oscillators that is motivated from atmospheric dynamics. The model is
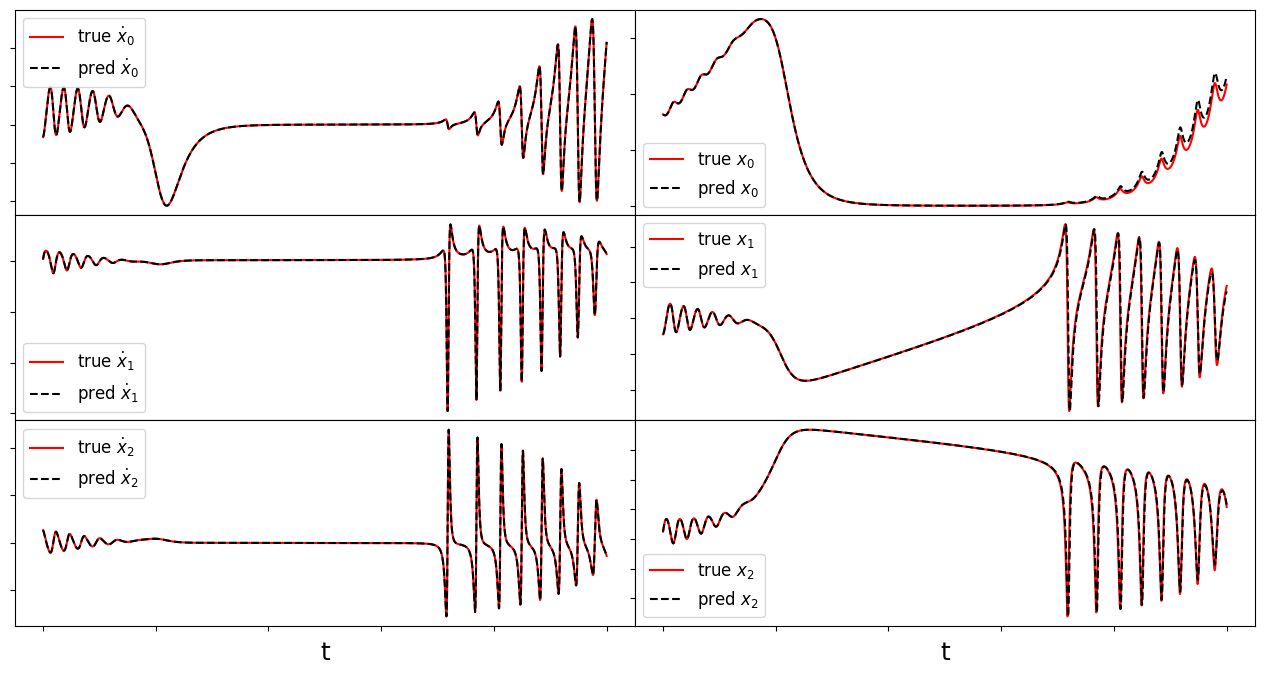
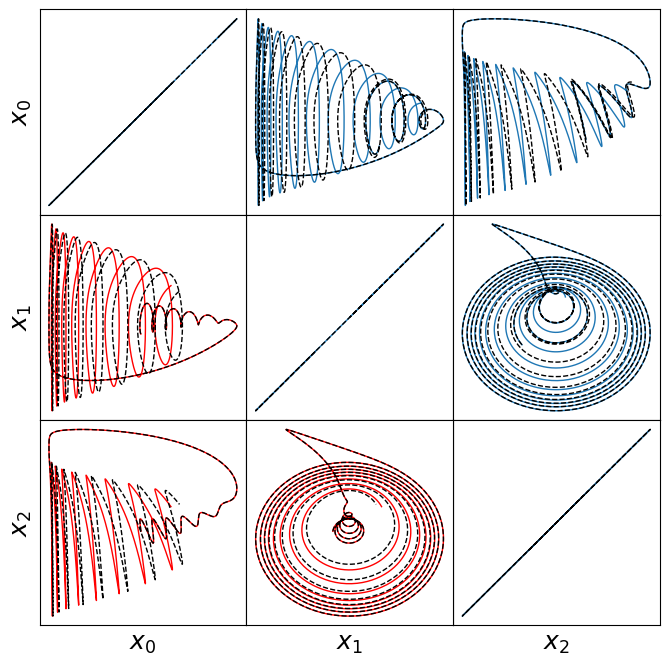
For comparison, we assume the parameter choices in Tuwankotta et al. (2006), \(\mu_1 = 0.05\), \(\mu_2 = -0.01\), \(\omega = 3\), \(\sigma = 1.1\), \(\kappa = -2\), and \(\beta = -6\), for which a limit cycle is known to exist. Again, the algorithm shows straightforward success finding a model with a trapping region, for a range of hyperparameter values.
[4]:
# define parameters
r = 3
sigma = 1.1
beta = -5.0
eps = 0.01
k1 = 5
k2 = 1
mu1 = eps * k1
mu2 = -eps * k2
alpha = -2.0
omega = 3.0
# Make training and testing data
dt = 0.01
T = 100
t = np.arange(0, T + dt, dt)
t_span = (t[0], t[-1])
x0 = rng.random((3,)) - 0.5
x_train = solve_ivp(
oscillator,
t_span,
x0,
t_eval=t,
args=(mu1, mu2, omega, alpha, beta, sigma),
**integrator_keywords
).y.T
x0 = rng.random((3,)) - 0.5
x_test = solve_ivp(
oscillator,
t_span,
x0,
t_eval=t,
args=(mu1, mu2, omega, alpha, beta, sigma),
**integrator_keywords
).y.T
# define hyperparameters
eta = 1.0e8
# run trapping SINDy, reusing previous reg_weight_lam, max_iter and constraints
sindy_opt = ps.TrappingSR3(
_n_tgts=3,
_include_bias=True,
reg_weight_lam=reg_weight_lam,
eta=eta,
max_iter=max_iter,
verbose=True
)
model = ps.SINDy(
optimizer=sindy_opt,
feature_library=sindy_library,
differentiation_method=ps.FiniteDifference(drop_endpoints=True),
)
model.fit(x_train, t=t)
model.print()
Xi = model.coefficients().T
xdot_test = model.differentiate(x_test, t=t)
xdot_test_pred = model.predict(x_test)
x_train_pred = model.simulate(x_train[0, :], t, integrator_kws=integrator_keywords)
x_test_pred = model.simulate(x_test[0, :], t, integrator_kws=integrator_keywords)
PL_tensor = sindy_opt.PL_
PQ_tensor = sindy_opt.PQ_
L = np.tensordot(PL_tensor, Xi, axes=([3, 2], [0, 1]))
Q = np.tensordot(PQ_tensor, Xi, axes=([4, 3], [0, 1]))
Q_sum = np.max(np.abs((Q + np.transpose(Q, [1, 2, 0]) + np.transpose(Q, [2, 0, 1]))))
print("Max deviation from the constraints = ", Q_sum)
# plotting and analysis
make_fits(r, t, xdot_test, xdot_test_pred, x_test, x_test_pred, "oscillator")
make_lissajou(r, x_train, x_test, x_train_pred, x_test_pred, "oscillator")
E_pred = np.linalg.norm(x_test - x_test_pred) / np.linalg.norm(x_test)
print("Frobenius error = ", E_pred)
mean_val = np.mean(x_test_pred, axis=0)
mean_val = np.sqrt(np.sum(mean_val**2))
check_local_stability(Xi, sindy_opt, mean_val)
# compute relative Frobenius error in the model coefficients
terms = sindy_library.get_feature_names()
Xi_oscillator = np.zeros(Xi.shape)
Xi_oscillator[1 : r + 1, :] = np.asarray(
[[mu1, 0, 0], [0, mu2, omega], [0, -omega, mu2]]
).T
Xi_oscillator[terms.index("x0 x1"), 0] = sigma
Xi_oscillator[terms.index("x1 x2"), 1] = alpha
Xi_oscillator[terms.index("x0^2"), 1] = -sigma
Xi_oscillator[terms.index("x2^2"), 1] = beta
Xi_oscillator[terms.index("x1 x2"), 2] = -beta
Xi_oscillator[terms.index("x1^2"), 2] = -alpha
coef_pred = np.linalg.norm(Xi_oscillator - Xi) / np.linalg.norm(Xi_oscillator)
print("Frobenius coefficient error = ", coef_pred)
# Compute time-averaged dX/dt error
deriv_error = np.zeros(xdot_test.shape[0])
for i in range(xdot_test.shape[0]):
deriv_error[i] = np.dot(
xdot_test[i, :] - xdot_test_pred[i, :], xdot_test[i, :] - xdot_test_pred[i, :]
) / np.dot(xdot_test[i, :], xdot_test[i, :])
print("Time-averaged derivative error = ", np.nanmean(deriv_error))
Iter ... |y-Xw|^2 ... |Pw-A|^2/eta ... |w|_1 ... |Qijk|/a ... |Qijk+...|/b ... Total:
0 ... 2.080e-04 ... 2.001e-07 ... 0.00e+00 ... 2.26e-19 ... 7.71e-50 ... 2.08e-04
500 ... 2.080e-04 ... 2.947e-10 ... 0.00e+00 ... 2.26e-19 ... 2.80e-49 ... 2.08e-04
1000 ... 2.080e-04 ... 1.632e-10 ... 0.00e+00 ... 2.26e-19 ... 4.53e-50 ... 2.08e-04
1500 ... 2.080e-04 ... 1.147e-10 ... 0.00e+00 ... 2.26e-19 ... 9.04e-49 ... 2.08e-04
2000 ... 2.080e-04 ... 8.962e-11 ... 0.00e+00 ... 2.26e-19 ... 5.17e-49 ... 2.08e-04
2500 ... 2.080e-04 ... 7.477e-11 ... 0.00e+00 ... 2.26e-19 ... 2.04e-49 ... 2.08e-04
3000 ... 2.080e-04 ... 6.526e-11 ... 0.00e+00 ... 2.26e-19 ... 1.32e-49 ... 2.08e-04
3500 ... 2.080e-04 ... 5.882e-11 ... 0.00e+00 ... 2.26e-19 ... 6.36e-50 ... 2.08e-04
4000 ... 2.080e-04 ... 5.430e-11 ... 0.00e+00 ... 2.26e-19 ... 3.40e-49 ... 2.08e-04
4500 ... 2.080e-04 ... 5.103e-11 ... 0.00e+00 ... 2.26e-19 ... 1.83e-49 ... 2.08e-04
(x0)' = 0.050 x0 + 1.100 x0 x1
(x1)' = 0.001 x0 + -0.010 x1 + 2.999 x2 + -1.100 x0^2 + -1.998 x1 x2 + -4.998 x2^2
(x2)' = -2.999 x1 + -0.010 x2 + 1.998 x1^2 + 4.998 x1 x2
Max deviation from the constraints = 2.2693435672294093e-15
Frobenius error = 0.0664282208845891
optimal m: [-0.18651656 -0.99701715 0.39842863]
As eigvals: [-5.78928194e+00 -1.05543550e+00 -1.40712551e-03]
0.5 * |tilde{H}_0|_F = 3.4667284016201907e-15
0.5 * |tilde{H}_0|_F^2 / beta = 2.4036411621200164e-49
Estimate of trapping region size, Rm = 2283.19477453083
Normalized trapping region size, Reff = 4958.76569356197
Local stability size, R_ls= 608841537993.607
Frobenius coefficient error = 0.0005373058299791525
Time-averaged derivative error = 5.467638269496836e-06
[5]:
# make 3D illustration of the trapping region
trapping_region(r, x_test_pred, Xi, sindy_opt, "Atmospheric Oscillator")
optimal m: [-0.18651656 -0.99701715 0.39842863]
As eigvals: [-5.78928194e+00 -1.05543550e+00 -1.40712551e-03]
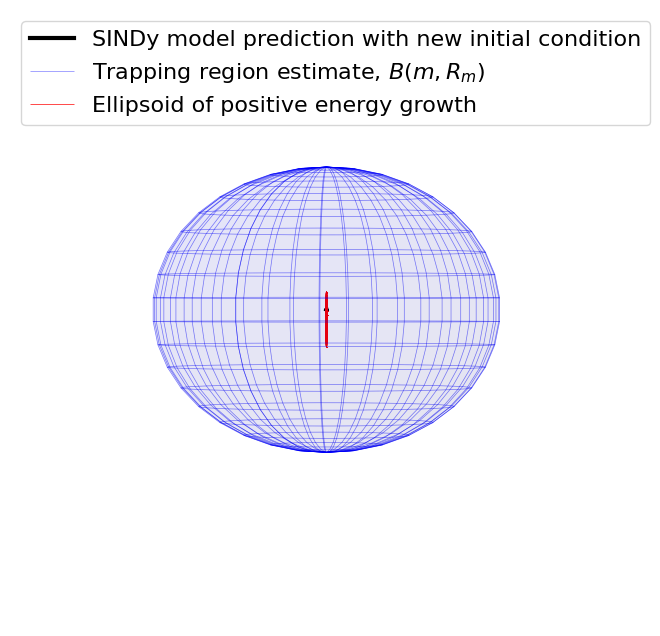
We identified a very accurate and provably stable model but the trapping region looks way too big… what’s going on here?
The estimate for the size of the trapping region is based on the smallest eigenvalue of \(\mathbf{A}^S\). But this system has a big scale-separation, leading to \(\lambda_1 = -0.01\) (while \(\lambda_3 = -5.4\)) and an estimate of the trapping region of \(R_m = d/\lambda_1 \approx 300\). This is because our estimate of the trapping region comes from the worst case scenario.
Lorenz model
The Lorenz system originates from a simple fluid model of atmospheric dynamics from Lorenz et al. (1963). This system is likely the most famous example of chaotic, nonlinear behavior despite the somewhat innocuous system of equations,
For Lorenz’s choice of parameters, \(\sigma = 10\), \(\rho = 28\), \(\beta = 8/3\), this system is known to exhibit a stable attractor. For \(\mathbf{m} = [0,m_2,\rho+\sigma]\) (\(m_1\) does not contribute to \(\mathbf{A}^S\) so we set it to zero),
so that if \(\lambda_{\pm} < 0\), then \(-2\sqrt{\sigma\beta} < m_2 < 2\sqrt{\sigma\beta}\). Our algorithm can successfully identify the optimal \(\mathbf{m}\), and can be used to identify the inequality bounds on \(m_2\) for stability.
[6]:
# define parameters
r = 3
# make training and testing data
dt = 0.01
T = 40
t = np.arange(0, T + dt, dt)
t_span = (t[0], t[-1])
x0 = [1, -1, 20]
x_train = solve_ivp(lorenz, t_span, x0, t_eval=t, **integrator_keywords).y.T
x0 = (rng.random(3) - 0.5) * 30
x_test = solve_ivp(lorenz, t_span, x0, t_eval=t, **integrator_keywords).y.T
# define hyperparameters
reg_weight_lam = 0
max_iter = 5000
eta = 1.0e3
alpha_m = 8e-1 * eta # default is 1e-2 * eta so this speeds up the code here
# run trapping SINDy
sindy_opt = ps.TrappingSR3(
_n_tgts=3,
_include_bias=True,
reg_weight_lam=reg_weight_lam,
eta=eta,
alpha_m=alpha_m,
max_iter=max_iter,
gamma=-1,
verbose=True,
)
model = ps.SINDy(
optimizer=sindy_opt,
feature_library=sindy_library,
differentiation_method=ps.FiniteDifference(drop_endpoints=True),
)
model.fit(x_train, t=t)
model.print()
Xi = model.coefficients().T
xdot_test = model.differentiate(x_test, t=t)
xdot_test_pred = model.predict(x_test)
x_train_pred = model.simulate(x_train[0, :], t, integrator_kws=integrator_keywords)
x_test_pred = model.simulate(x_test[0, :], t, integrator_kws=integrator_keywords)
# plotting and analysis
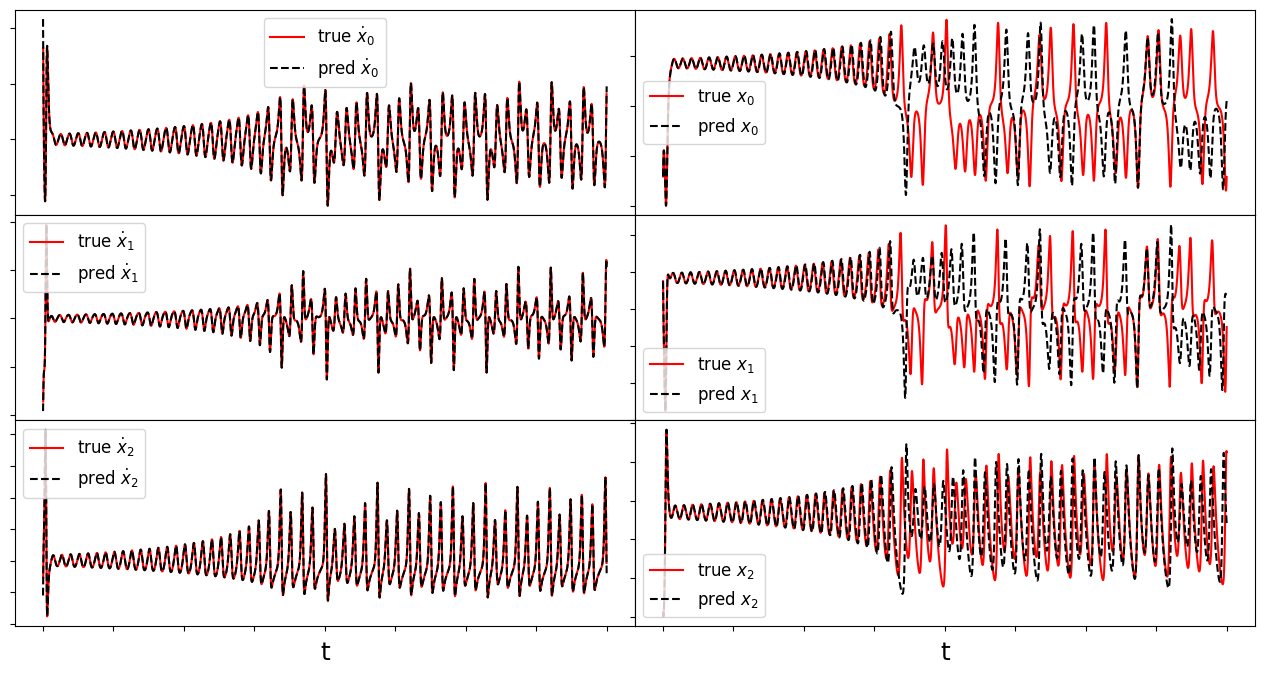
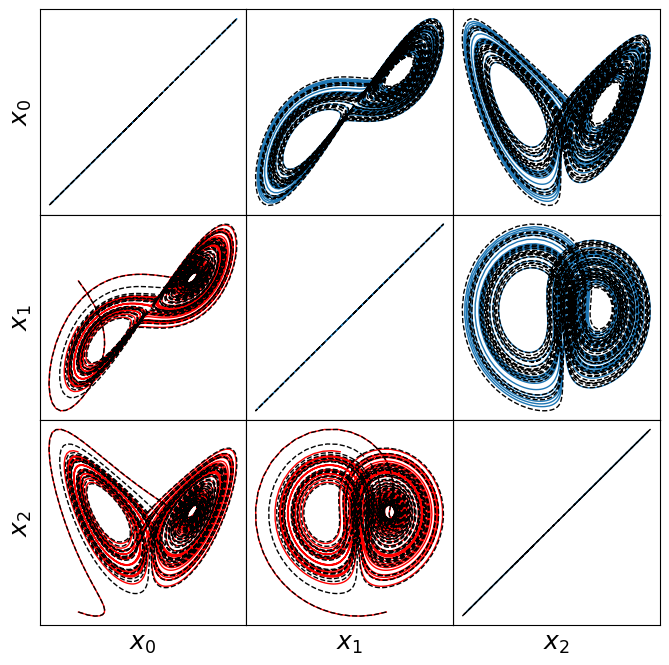
make_fits(r, t, xdot_test, xdot_test_pred, x_test, x_test_pred, "lorenz")
make_lissajou(r, x_train, x_test, x_train_pred, x_test_pred, "lorenz")
make_progress_plots(r, sindy_opt)
PL_tensor = sindy_opt.PL_
PQ_tensor = sindy_opt.PQ_
L = np.tensordot(PL_tensor, Xi, axes=([3, 2], [0, 1]))
Q = np.tensordot(PQ_tensor, Xi, axes=([4, 3], [0, 1]))
Q_sum = np.max(np.abs((Q + np.transpose(Q, [1, 2, 0]) + np.transpose(Q, [2, 0, 1]))))
print("Max deviation from the constraints = ", Q_sum)
mean_val = np.mean(x_test_pred, axis=0)
mean_val = np.sqrt(np.sum(mean_val**2))
check_local_stability(Xi, sindy_opt, mean_val)
E_pred = np.linalg.norm(x_test - x_test_pred) / np.linalg.norm(x_test)
print("Frobenius error = ", E_pred)
# compute relative Frobenius error in the model coefficients
sigma = 10
rho = 28
beta = 8.0 / 3.0
terms = sindy_library.get_feature_names()
Xi_lorenz = np.zeros(Xi.shape)
Xi_lorenz[1 : r + 1, :] = np.asarray(
[[-sigma, sigma, 0], [rho, -1, 0], [0, 0, -beta]]
).T
Xi_lorenz[terms.index("x0 x2"), 1] = -1
Xi_lorenz[terms.index("x0 x1"), 2] = 1
coef_pred = np.linalg.norm(Xi_lorenz - Xi) / np.linalg.norm(Xi_lorenz)
print("Frobenius coefficient error = ", coef_pred)
# Compute time-averaged dX/dt error
deriv_error = np.zeros(xdot_test.shape[0])
for i in range(xdot_test.shape[0]):
deriv_error[i] = np.dot(
xdot_test[i, :] - xdot_test_pred[i, :], xdot_test[i, :] - xdot_test_pred[i, :]
) / np.dot(xdot_test[i, :], xdot_test[i, :])
print("Time-averaged derivative error = ", np.nanmean(deriv_error))
Iter ... |y-Xw|^2 ... |Pw-A|^2/eta ... |w|_1 ... |Qijk|/a ... |Qijk+...|/b ... Total:
0 ... 2.475e+02 ... 1.272e-01 ... 0.00e+00 ... 4.93e-21 ... 1.66e-46 ... 2.48e+02
500 ... 2.475e+02 ... 2.420e-06 ... 0.00e+00 ... 4.93e-21 ... 7.80e-48 ... 2.47e+02
1000 ... 2.475e+02 ... 7.829e-07 ... 0.00e+00 ... 4.93e-21 ... 3.00e-47 ... 2.47e+02
1500 ... 2.475e+02 ... 4.622e-07 ... 0.00e+00 ... 4.93e-21 ... 1.11e-47 ... 2.47e+02
2000 ... 2.475e+02 ... 3.427e-07 ... 0.00e+00 ... 4.93e-21 ... 2.06e-47 ... 2.47e+02
2500 ... 2.475e+02 ... 2.849e-07 ... 0.00e+00 ... 4.93e-21 ... 4.68e-48 ... 2.47e+02
3000 ... 2.475e+02 ... 2.528e-07 ... 0.00e+00 ... 4.93e-21 ... 1.09e-47 ... 2.47e+02
3500 ... 2.475e+02 ... 2.336e-07 ... 0.00e+00 ... 4.93e-21 ... 2.81e-47 ... 2.47e+02
4000 ... 2.475e+02 ... 2.215e-07 ... 0.00e+00 ... 4.93e-21 ... 3.92e-48 ... 2.47e+02
4500 ... 2.475e+02 ... 2.136e-07 ... 0.00e+00 ... 4.93e-21 ... 2.71e-47 ... 2.47e+02
(x0)' = 0.090 1 + -9.861 x0 + 9.937 x1 + -0.013 x2 + -0.001 x0 x1 + -0.003 x0 x2 + 0.001 x1^2
(x1)' = -0.341 1 + 27.751 x0 + -0.914 x1 + 0.041 x2 + 0.001 x0^2 + -0.001 x0 x1 + -0.993 x0 x2 + -0.002 x1 x2 + -0.001 x2^2
(x2)' = 0.086 1 + 0.002 x0 + -0.015 x1 + -2.664 x2 + 0.003 x0^2 + 0.992 x0 x1 + 0.002 x1^2 + 0.001 x1 x2
Max deviation from the constraints = 2.761679773755077e-14
optimal m: [-1.07188213 -0.11754436 37.86515422]
As eigvals: [-9.97039848 -2.66340876 -0.9795892 ]
0.5 * |tilde{H}_0|_F = 2.6149378149666363e-14
0.5 * |tilde{H}_0|_F^2 / beta = 1.3675799552284973e-47
Estimate of trapping region size, Rm = 103.718100343866
Normalized trapping region size, Reff = 4.13798971688560
Local stability size, R_ls= 56191921314719.0
Frobenius error = 0.5528540831430481
Frobenius coefficient error = 0.015099589869550933
Time-averaged derivative error = 1.2372728274442115e-05
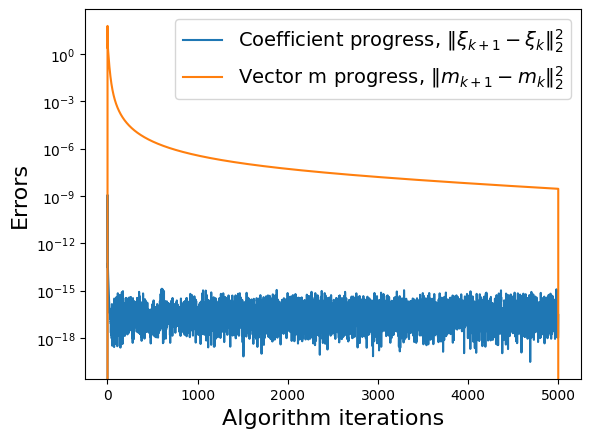
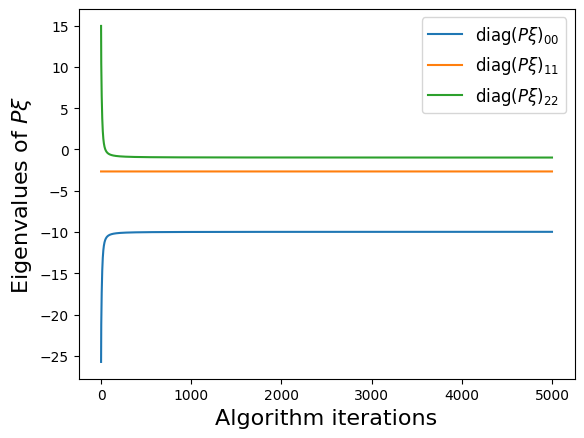
Visualizing the trapping region for Lorenz
Below, we plot the SINDy-identified trapping region (red) and the analytic trapping region (cyan) for the Lorenz system. The estimate for the trapping region (blue) correctly encloses the Lorenz attractor, and the red ellipsoid of positive energy growth. We can see that trajectories starting outside of this region monotonically fall into this region and remain forever, and the red and cyan ellipsoids agree well.
[7]:
# make 3D illustration of the trapping region
trapping_region(r, x_test_pred, Xi, sindy_opt, "Lorenz Attractor")
optimal m: [-1.07188213 -0.11754436 37.86515422]
As eigvals: [-9.97039848 -2.66340876 -0.9795892 ]
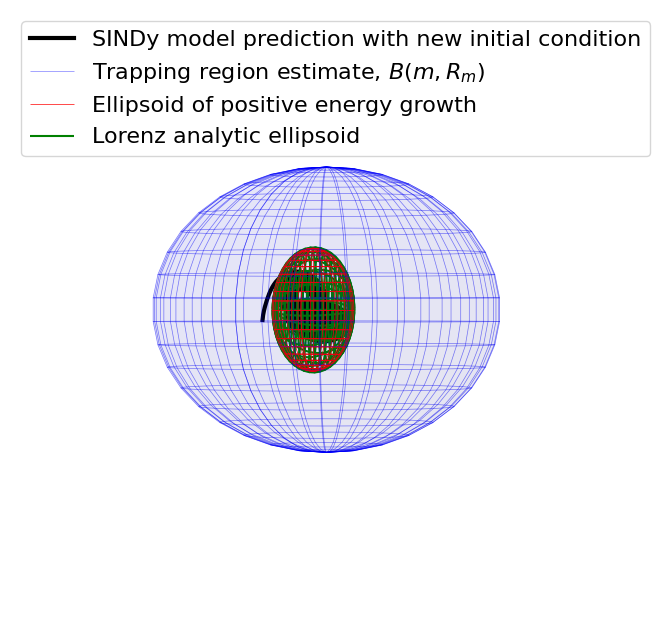
Some of these plots are different looking than in the Trapping SINDy paper
This is because (1) there were a few small errors in the original code and (2) we are now plotting the trapping regions not in the \(\mathbf{a}(t)\) or \(\mathbf{y}(t) = \mathbf{a}(t) - \mathbf{m}\) spaces, but instead in the \(\mathbf{z}(t)\) eigenvector coordinates of \(\mathbf{A}^S\), where the definition of the ellipsoid makes the most sense, and (3) the paper examples are typically generated from fully converged solutions run for many additional iterations. See the paper for a review of this notation.
MHD model
Magnetohydrodynamics exhibit quadratic nonlinearities that are often energy-preserving with typical boundary conditions. We consider a simple model of the nonlinearity in 2D incompressible MHD, which can be obtained from Fourier-Galerkin projection onto a single triad of wave vectors. For the wave vectors \((1,1)\), \((2,-1)\), and \((3,0)\) and no background magnetic field, the Carbone and Veltri (1992) system is
where \(\nu \geq 0\) is the viscosity and \(\mu \geq 0\) is the resistivity. Without external forcing, this system is trivially stable (it dissipates to zero), so we consider the inviscid limit \(\nu = \mu = 0\). The system is then Hamiltonian and our algorithm correctly converges to \(\mathbf{m} = 0\), \(\mathbf{A}^S = 0\). The reason our algorithm converges to the correct behavior is because it is still minimizing \(\dot{K}\); in this case trapping SINDy minimizes to \(\dot{K} \approx 0\) and can make no further improvement.
[14]:
# define parameters
r = 6
nu = 0.0 # viscosity
mu = 0.0 # resistivity
# define training and testing data (low resolution)
dt = 0.02
T = 40
t = np.arange(0, T + dt, dt)
t_span = (t[0], t[-1])
x0 = rng.random((6,)) - 0.5
x_train = solve_ivp(mhd, t_span, x0, t_eval=t, **integrator_keywords).y.T
x0 = rng.random((6,)) - 0.5
x_test = solve_ivp(mhd, t_span, x0, t_eval=t, **integrator_keywords).y.T
# define hyperparameters
reg_weight_lam = 0.0
max_iter = 1000
eta = 1.0e10
alpha_m = 9.0e-1 * eta
sindy_opt = ps.TrappingSR3(
_n_tgts=6,
_include_bias=True,
reg_weight_lam=reg_weight_lam,
eta=eta,
max_iter=max_iter,
verbose=True,
)
# eps_solver=1e-3) # reduce the solver tolerance for speed
model = ps.SINDy(
optimizer=sindy_opt,
feature_library=sindy_library,
differentiation_method=ps.FiniteDifference(drop_endpoints=True),
)
model.fit(x_train, t=t)
model.print()
Xi = model.coefficients().T
xdot_test = model.differentiate(x_test, t=t)
xdot_test_pred = model.predict(x_test)
x_train_pred = model.simulate(x_train[0, :], t, integrator_kws=integrator_keywords)
x_test_pred = model.simulate(x_test[0, :], t, integrator_kws=integrator_keywords)
PL_tensor = sindy_opt.PL_
PQ_tensor = sindy_opt.PQ_
L = np.tensordot(PL_tensor, Xi, axes=([3, 2], [0, 1]))
Q = np.tensordot(PQ_tensor, Xi, axes=([4, 3], [0, 1]))
Q_sum = np.max(np.abs((Q + np.transpose(Q, [1, 2, 0]) + np.transpose(Q, [2, 0, 1]))))
print("Max deviation from the constraints = ", Q_sum)
# plotting and analysis
make_lissajou(r, x_train, x_test, x_train_pred, x_test_pred, "mhd")
mean_val = np.mean(x_test_pred, axis=0)
mean_val = np.sqrt(np.sum(mean_val**2))
check_local_stability(Xi, sindy_opt, mean_val)
E_pred = np.linalg.norm(x_test - x_test_pred) / np.linalg.norm(x_test)
print(E_pred)
# compute relative Frobenius error in the model coefficients
terms = sindy_library.get_feature_names(
input_features=["V1", "V2", "V3", "B1", "B2", "B3"]
)
Xi_mhd = np.zeros(Xi.shape)
Xi_mhd[terms.index("V2 V3"), 0] = 4.0
Xi_mhd[terms.index("B2 B3"), 0] = -4.0
Xi_mhd[terms.index("V1 V3"), 1] = -7
Xi_mhd[terms.index("B1 B3"), 1] = 7.0
Xi_mhd[terms.index("V1 V2")] = 3.0
Xi_mhd[terms.index("B1 B2"), 2] = -3.0
Xi_mhd[terms.index("V2 B3"), 3] = 2.0
Xi_mhd[terms.index("V3 B2"), 3] = -2.0
Xi_mhd[terms.index("V1 B3"), 4] = -5.0
Xi_mhd[terms.index("V3 B1"), 4] = 5.0
Xi_mhd[terms.index("V1 B2"), 5] = 9.0
Xi_mhd[terms.index("V2 B1"), 5] = -9.0
model.print(precision=2)
coef_pred = np.linalg.norm(Xi_mhd - Xi) / np.linalg.norm(Xi_mhd)
# Compute time-averaged dX/dt error
deriv_error = np.zeros(xdot_test.shape[0])
for i in range(xdot_test.shape[0]):
deriv_error[i] = np.dot(
xdot_test[i, :] - xdot_test_pred[i, :], xdot_test[i, :] - xdot_test_pred[i, :]
) / np.dot(xdot_test[i, :], xdot_test[i, :])
print("Time-averaged derivative error = ", np.nanmean(deriv_error))
Iter ... |y-Xw|^2 ... |Pw-A|^2/eta ... |w|_1 ... |Qijk|/a ... |Qijk+...|/b ... Total:
0 ... 1.216e-04 ... 1.068e-08 ... 0.00e+00 ... 9.14e-19 ... 4.48e-44 ... 1.22e-04
100 ... 1.216e-04 ... 4.185e-11 ... 0.00e+00 ... 9.14e-19 ... 2.77e-43 ... 1.22e-04
200 ... 1.216e-04 ... 5.575e-12 ... 0.00e+00 ... 9.14e-19 ... 2.26e-44 ... 1.22e-04
300 ... 1.216e-04 ... 3.044e-12 ... 0.00e+00 ... 9.14e-19 ... 2.29e-43 ... 1.22e-04
400 ... 1.216e-04 ... 2.998e-12 ... 0.00e+00 ... 9.14e-19 ... 3.65e-44 ... 1.22e-04
(x0)' = 4.002 x1 x2 + -0.002 x1 x5 + -0.004 x2 x4 + -0.001 x2 x5 + -3.994 x4 x5
(x1)' = -0.002 x2 + 0.014 x5 + -6.991 x0 x2 + -0.001 x0 x4 + -0.013 x0 x5 + -0.001 x1 x3 + 0.009 x2 x3 + 0.001 x3 x4 + 6.959 x3 x5
(x2)' = 0.007 x1 + -0.007 x4 + 0.001 x5 + 2.988 x0 x1 + 0.010 x0 x4 + -0.001 x0 x5 + -0.012 x1 x3 + -2.988 x3 x4 + -0.003 x3 x5
(x3)' = 0.001 x1^2 + 0.003 x1 x2 + 1.990 x1 x5 + -2.000 x2 x4 + 0.003 x4 x5
(x4)' = 0.001 x1 + 0.006 x2 + -0.005 x5 + -0.006 x0 x2 + -4.981 x0 x5 + -0.001 x1 x3 + 4.989 x2 x3 + 0.008 x3 x5
(x5)' = -0.019 x1 + -0.001 x2 + 0.006 x4 + 0.015 x0 x1 + 0.001 x0 x2 + 8.975 x0 x4 + -8.949 x1 x3 + 0.002 x2 x3 + -0.010 x3 x4
Max deviation from the constraints = 2.7498003873915877e-12
optimal m: [ 3.21679047e-04 8.28318584e-06 -6.38279005e-06 -1.77840949e-03
-2.96212872e-06 -9.51704477e-06]
As eigvals: [-3.18979925e-03 -3.94994617e-04 -7.69816688e-05 4.92252189e-06
2.08867820e-04 3.09362678e-03]
0.5 * |tilde{H}_0|_F = 3.89305279321273e-12
0.5 * |tilde{H}_0|_F^2 / beta = 3.0311720101482877e-43
Estimate of trapping region size, Rm = -1191979768.28214
Normalized trapping region size, Reff = -2685179915.75110
Local stability size, R_ls= -0.0392666912754283
0.10863468891484956
(x0)' = 4.00 x1 x2 + -3.99 x4 x5
(x1)' = 0.01 x5 + -6.99 x0 x2 + -0.01 x0 x5 + 0.01 x2 x3 + 6.96 x3 x5
(x2)' = 0.01 x1 + -0.01 x4 + 2.99 x0 x1 + 0.01 x0 x4 + -0.01 x1 x3 + -2.99 x3 x4
(x3)' = 1.99 x1 x5 + -2.00 x2 x4
(x4)' = 0.01 x2 + -0.01 x0 x2 + -4.98 x0 x5 + 4.99 x2 x3 + 0.01 x3 x5
(x5)' = -0.02 x1 + 0.01 x4 + 0.02 x0 x1 + 8.98 x0 x4 + -8.95 x1 x3 + -0.01 x3 x4
Time-averaged derivative error = 2.18308749438043e-06

Forced Burger’s Equation
The viscous Burgers’ equation has long served as a simplified one-dimensional turbulence analogue (Burgers/Hopf 1948). The forced, viscous Burgers’ equation on a periodic domain \(x \in [0,2\pi)\) is:
where \(\nu\) is viscosity and the constant \(U\) models mean-flow advection. We project this system onto a Fourier basis and assume constant forcing acting on the largest scale, i.e. \(g(x, t) = \sigma \left( a_1(t) e^{ix} + a_{-1}(t) e^{-ix} \right)\) as in Noack and Schlegel et al. (2008). After Fourier projection, the evolution of the coefficients \(a_k(t)\) is given by the Galerkin dynamics
In the subcritical case \(\sigma < \nu\) the origin of this system is stable to all perturbations and all solutions decay on long times. However, in the supercritical case \(\sigma > \nu\) the excess energy input from the forcing cascades to the smaller dissipative scales. The absolute equilibrium limit \(\sigma = \nu = 0\) has a Hamiltonian structure; at long times the coefficients approach thermodynamic equilibrium and equipartition of energy. For the supercritical condition \(\sigma > \nu\), the trapping SINDy algorithm does not converge to a negative definite \(\mathbf{A}^S\) because this system does not exhibit effective nonlinearity.
We do not make a trapping SINDy model here because it takes a while to run. Instead, we show below that it does not fit the criteria of being effectively nonlinear.
[9]:
# define parameters and load in training DNS data
tstart = 0
tend = 3000
Burgers = sio.loadmat("../data/burgers_highres2.mat")
skip = 1
nu = Burgers["nu"].item()
sigma = Burgers["sigma"].item()
U = Burgers["U"].item()
t = (Burgers["t"].flatten())[tstart:tend:skip]
x_train = Burgers["a"]
u_train = Burgers["u"][:, tstart:tend:skip]
theta = Burgers["x"].flatten()
spatial_modes_train = Burgers["theta"]
r = 10
x_train = x_train[:r, tstart:tend:skip].T
Forced Burgers’ system is not effectively nonlinear
The last bit of information we will get from this system is checking if the analytic model exhibits effective nonlinearity, a requirement for the Schlegel and Noack trapping theorem to hold.
Using a simulated annealing algorithm, we can show that even the analytic 10D Galerkin Noack and Schlegel et al. (2008) model does not exhibit a \(\mathbf{m}\) such that \(\mathbf{A}\)^S is negative definite. This is because the nonlinearity is not ‘effective’.
[10]:
from scipy.optimize import dual_annealing as anneal_algo
# get analytic L and Q operators and galerkin model
L, Q = burgers_galerkin(sigma, nu, U)
rhs = lambda t, a: galerkin_model(a, L, Q) # noqa: E731
# Generate initial condition from unstable eigenvectors
lamb, Phi = np.linalg.eig(L)
idx = np.argsort(-np.real(lamb))
lamb, Phi = lamb[idx], Phi[:, idx]
a0 = np.real(1e-4 * Phi[:, :2] @ rng.random((2)))
# define parameters
dt = 1e-3
r = 10
t_sim = np.arange(0, 300, dt)
t_span = (t_sim[0], t_sim[-1])
x_train = solve_ivp(rhs, t_span, a0, t_eval=t_sim, **integrator_keywords).y.T
# Search between -500, 500 for each component of m
boundvals = np.zeros((r, 2))
boundmax = 500
boundmin = -500
boundvals[:, 0] = boundmin
boundvals[:, 1] = boundmax
# run simulated annealing and display optimal m and
# the corresponding objective function value
Ls = 0.5 * (L + L.T)
# obj_function defined in the utils python file
algo_sol = anneal_algo(
obj_function, bounds=boundvals, args=(Ls, Q, np.eye(r)), maxiter=2000
)
opt_m = algo_sol.x
opt_energy = algo_sol.fun
opt_result = algo_sol.message
print("Simulated annealing ended because " + opt_result[0])
print("Optimal m = ", opt_m)
print(
"Algorithm managed to reduce the largest eigenvalue of A^S to eig1 = ", opt_energy
)
print(
"Since the largest eigenvalue cannot be made negative, "
"we conclude that effective nonlinearity does not hold for this system."
)
Simulated annealing ended because Maximum number of iteration reached
Optimal m = [ 2.31048743e-03 -2.58898539e-03 -4.92962205e-06 -3.96749078e-06
3.37881574e-04 -4.38205503e-06 2.71145255e-04 -1.29874660e-04
3.58953385e-04 -9.35742513e-05]
Algorithm managed to reduce the largest eigenvalue of A^S to eig1 = 0.07500725791262655
Since the largest eigenvalue cannot be made negative, we conclude that effective nonlinearity does not hold for this system.
Von Karman shedding behind circular cylinder, Re = 100
In many cases, the wake behind a bluff body is characterized by a periodic vortex shedding phenomenon known as a von Karman street. The two-dimensional incompressible flow past a cylinder is a stereotypical example of such behavior.
The transient energy growth and saturation amplitude of this instability mode is of particular interest and has historically posed a significant modeling challenge. Noack et al. (2003) used an 8-mode POD basis that was augmented with a ninth “shift mode” parameterizing a mean flow deformation. The 9-mode quadratic Galerkin model does resolve the transient dynamics, nonlinear stability mechanism, and post-transient oscillation, accurately reproducing all of the key physical features of the vortex street. Moreover, in Schlegel and Noack (2015) stability of the quadratic model was proven with \(m_9 = m_\text{shift} = \epsilon\), \(\epsilon > 1\), and \(m_i = 0\) for \(i = \{1,...,8\}\). Note that POD-Galerkin models will generally weakly satisfy the effective nonlinearity criteria, although the addition of the shift-mode is a complication.
[11]:
# define parameters and load in POD modes obtained from DNS
a = np.loadtxt("../data/vonKarman_pod/vonKarman_a.dat")
t = a[:, 0]
r = 5
a_temp = a[:, 1:r]
a_temp = np.hstack((a_temp, a[:, -1].reshape(3000, 1)))
a = a_temp
tbegin = 0
tend = 3000
skip = 1
t = t[tbegin:tend:skip]
a = a[tbegin:tend:skip, :]
dt = t[1] - t[0]
# define the POD-Galerkin models from Noack (2003)
galerkin9 = sio.loadmat("../data/vonKarman_pod/galerkin9.mat")
# make the Galerkin model nonlinearity exactly energy-preserving
# rather than just approximately energy-preserving
gQ = 0.5 * (galerkin9["Q"] + np.transpose(galerkin9["Q"], [0, 2, 1]))
galerkin9["Q"] = (
gQ
- (
gQ
+ np.transpose(gQ, [1, 0, 2])
+ np.transpose(gQ, [2, 1, 0])
+ np.transpose(gQ, [0, 2, 1])
+ np.transpose(gQ, [2, 0, 1])
+ np.transpose(gQ, [1, 2, 0])
)
/ 6.0
)
# time base for simulating Galerkin models
t_sim = np.arange(0, 500, dt)
# Generate initial condition from unstable eigenvectors
lamb, Phi = np.linalg.eig(galerkin9["L"])
idx = np.argsort(-np.real(lamb))
lamb, Phi = lamb[idx], Phi[:, idx]
a0 = np.zeros(9)
a0[0] = 1e-3
# np.real( 1e-3 * Phi[:, :2] @ rng.random((2)) )
# get the 5D POD-Galerkin coefficients
inds5 = np.ix_([0, 1, 2, 3, -1], [0, 1, 2, 3, -1])
galerkin5 = {}
galerkin5["L"] = galerkin9["L"][inds5]
inds5 = np.ix_([0, 1, 2, 3, -1], [0, 1, 2, 3, -1], [0, 1, 2, 3, -1])
galerkin5["Q"] = galerkin9["Q"][inds5]
model5 = lambda t, a: galerkin_model(a, galerkin5["L"], galerkin5["Q"]) # noqa: E731
# make the 3D, 5D, and 9D POD-Galerkin trajectories
t_span = (t[0], t[-1])
a_galerkin5 = solve_ivp(model5, t_span, a0[:5], t_eval=t, **integrator_keywords).y.T
adot_galerkin5 = np.gradient(a_galerkin5, axis=0) / (t[1] - t[0])
# plot the first 4 POD modes + the shift mode
mode_numbers = [0, 1, 2, 3, -1]
plt.figure(figsize=(12, 8))
for i in range(r):
plt.subplot(r, 1, i + 1)
if i == 0:
plt.title(
"DNS and POD-Galerkin models on first 4 POD modes + shift mode", fontsize=16
)
plt.plot(t, a[:, mode_numbers[i]], "r", label="POD from DNS")
plt.plot(t, a_galerkin5[:, mode_numbers[i]], "b", label="POD-5 model")
ax = plt.gca()
plt.ylabel(r"$a_{" + str(mode_numbers[i]) + "}$", fontsize=20)
plt.grid(True)
if i == r - 1:
plt.xlabel("t", fontsize=18)
plt.legend(loc="upper left", fontsize=16)
else:
ax.set_xticklabels([])
plt.yticks(fontsize=16)
plt.xticks(fontsize=16)
a0 = np.zeros(r)
a0[0] = 1e-3
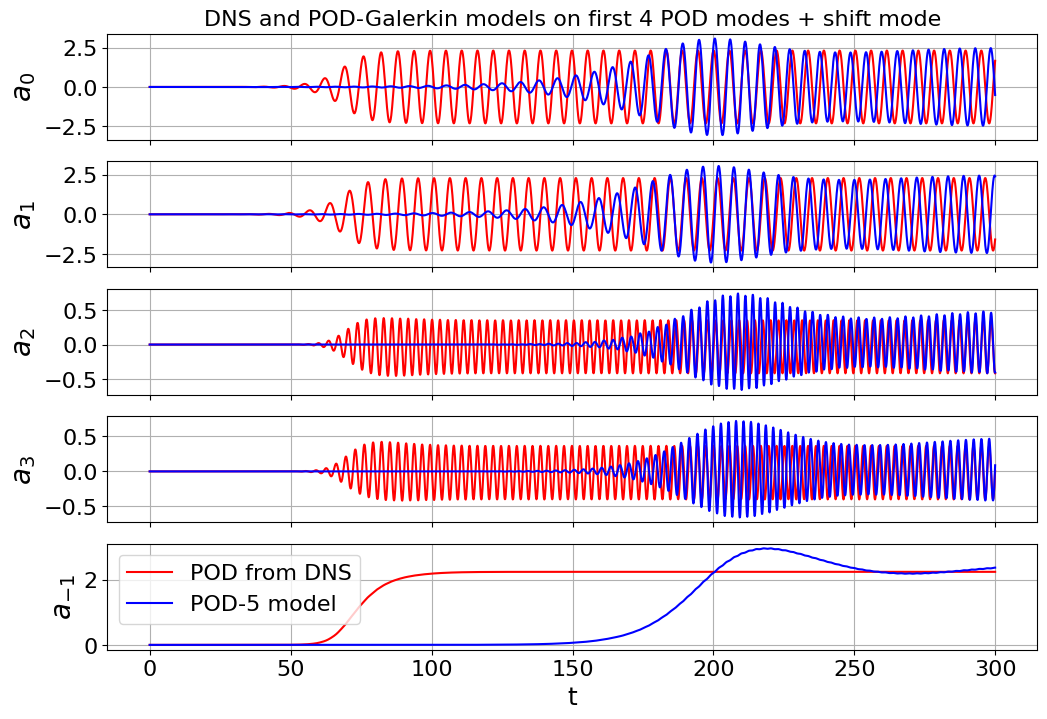
[12]:
# same test and train trajectory for simplicity here
a = np.loadtxt("../data/vonKarman_pod/vonKarman_a.dat")
t = a[:, 0]
r = 5
a_temp = a[:, 1:r]
a_temp = np.hstack((a_temp, a[:, -1].reshape(3000, 1)))
a = a_temp
tbegin = 0
tend = 3000
skip = 1
t = t[tbegin:tend:skip]
a = a[tbegin:tend:skip, :]
dt = t[1] - t[0]
x_train = a
x_test = a
# define hyperparameters
max_iter = 10000
eta = 1.0
# don't need a reg_weight_lam if eta is sufficiently small
# which is good news because CVXPY is much slower
reg_weight_lam = 0
alpha_m = 1e-1 * eta
# run trapping SINDy
sindy_opt = ps.TrappingSR3(
_n_tgts=5,
_include_bias=False,
reg_weight_lam=reg_weight_lam,
eta=eta,
alpha_m=alpha_m,
max_iter=max_iter,
verbose=True,
)
model = ps.SINDy(
optimizer=sindy_opt,
feature_library=sindy_library_no_bias,
differentiation_method=ps.FiniteDifference(drop_endpoints=True),
)
model.fit(x_train, t=t)
Xi = model.coefficients().T
xdot_test = model.differentiate(x_test, t=t)
xdot_test_pred = model.predict(x_test)
PL_tensor = sindy_opt.PL_
PQ_tensor = sindy_opt.PQ_
L = np.tensordot(PL_tensor, Xi, axes=([3, 2], [0, 1]))
Q = np.tensordot(PQ_tensor, Xi, axes=([4, 3], [0, 1]))
Q_sum = np.max(np.abs((Q + np.transpose(Q, [1, 2, 0]) + np.transpose(Q, [2, 0, 1]))))
print("Max deviation from the constraints = ", Q_sum)
if check_local_stability(Xi, sindy_opt, 1):
x_train_pred = model.simulate(x_train[0, :], t, integrator_kws=integrator_keywords)
x_test_pred = model.simulate(a0, t, integrator_kws=integrator_keywords)
make_progress_plots(r, sindy_opt)
# plotting and analysis
make_fits(r, t, xdot_test, xdot_test_pred, x_test, x_test_pred, "vonKarman")
make_lissajou(r, x_train, x_test, x_train_pred, x_test_pred, "VonKarman")
mean_val = np.mean(x_test_pred, axis=0)
mean_val = np.sqrt(np.sum(mean_val**2))
check_local_stability(Xi, sindy_opt, mean_val)
A_guess = sindy_opt.A_history_[-1]
m_guess = sindy_opt.m_history_[-1]
E_pred = np.linalg.norm(x_test - x_test_pred) / np.linalg.norm(x_test)
print("Frobenius Error = ", E_pred)
make_progress_plots(r, sindy_opt)
# Compute time-averaged dX/dt error
deriv_error = np.zeros(xdot_test.shape[0])
for i in range(xdot_test.shape[0]):
deriv_error[i] = np.dot(
xdot_test[i, :] - xdot_test_pred[i, :], xdot_test[i, :] - xdot_test_pred[i, :]
) / np.dot(xdot_test[i, :], xdot_test[i, :])
print("Time-averaged derivative error = ", np.nanmean(deriv_error))
Iter ... |y-Xw|^2 ... |Pw-A|^2/eta ... |w|_1 ... |Qijk|/a ... |Qijk+...|/b ... Total:
0 ... 8.894e-01 ... 7.929e-02 ... 0.00e+00 ... 4.06e-22 ... 5.00e-45 ... 9.69e-01
1000 ... 8.785e-01 ... 5.941e-02 ... 0.00e+00 ... 5.97e-22 ... 3.24e-45 ... 9.38e-01
2000 ... 8.763e-01 ... 5.426e-02 ... 0.00e+00 ... 6.35e-22 ... 5.42e-45 ... 9.31e-01
3000 ... 8.753e-01 ... 5.104e-02 ... 0.00e+00 ... 6.67e-22 ... 8.45e-45 ... 9.26e-01
4000 ... 8.747e-01 ... 4.874e-02 ... 0.00e+00 ... 6.93e-22 ... 2.03e-45 ... 9.23e-01
5000 ... 8.742e-01 ... 4.688e-02 ... 0.00e+00 ... 7.16e-22 ... 6.48e-45 ... 9.21e-01
6000 ... 8.738e-01 ... 4.503e-02 ... 0.00e+00 ... 7.37e-22 ... 2.85e-45 ... 9.19e-01
7000 ... 8.731e-01 ... 4.269e-02 ... 0.00e+00 ... 7.57e-22 ... 6.19e-45 ... 9.16e-01
8000 ... 8.719e-01 ... 3.837e-02 ... 0.00e+00 ... 7.77e-22 ... 5.94e-45 ... 9.10e-01
9000 ... 8.681e-01 ... 2.328e-02 ... 0.00e+00 ... 8.15e-22 ... 1.15e-44 ... 8.91e-01
Max deviation from the constraints = 1.3642420526593924e-12
optimal m: [-0.0104195 -0.01689565 -0.11558045 -0.74053773 2.57118063]
As eigvals: [-0.18423098 -0.09651067 -0.07401776 -0.01759789 -0.01134589]
0.5 * |tilde{H}_0|_F = 1.3043281760792713e-12
0.5 * |tilde{H}_0|_F^2 / beta = 3.402543981828557e-44
Estimate of trapping region size, Rm = 131.619706082290
Local stability size, R_ls= 13047975120.9099
optimal m: [-0.0104195 -0.01689565 -0.11558045 -0.74053773 2.57118063]
As eigvals: [-0.18423098 -0.09651067 -0.07401776 -0.01759789 -0.01134589]
0.5 * |tilde{H}_0|_F = 1.3043281760792713e-12
0.5 * |tilde{H}_0|_F^2 / beta = 3.402543981828557e-44
Estimate of trapping region size, Rm = 131.619706082290
Normalized trapping region size, Reff = 75.9754280467269
Local stability size, R_ls= 13047975120.9099
Frobenius Error = 0.6535742642113395
Time-averaged derivative error = 0.00236849161203658
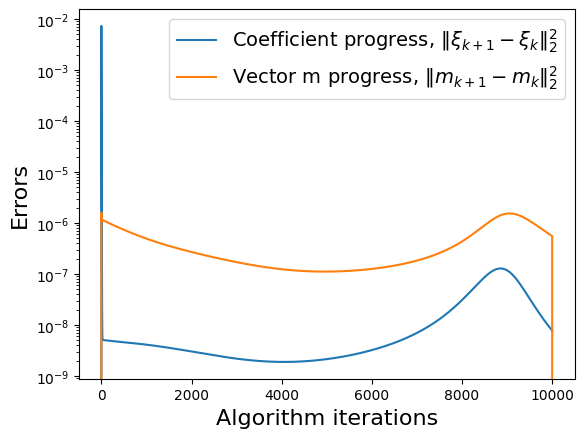
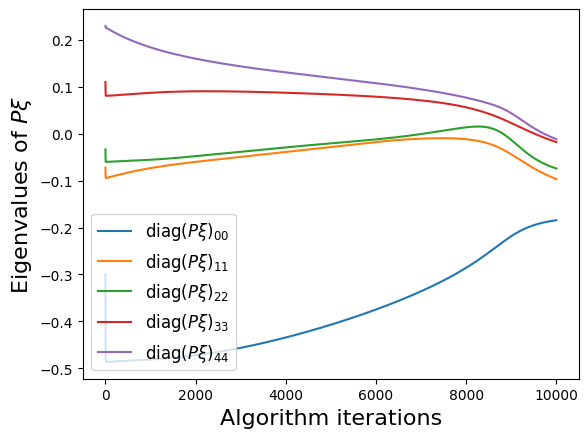
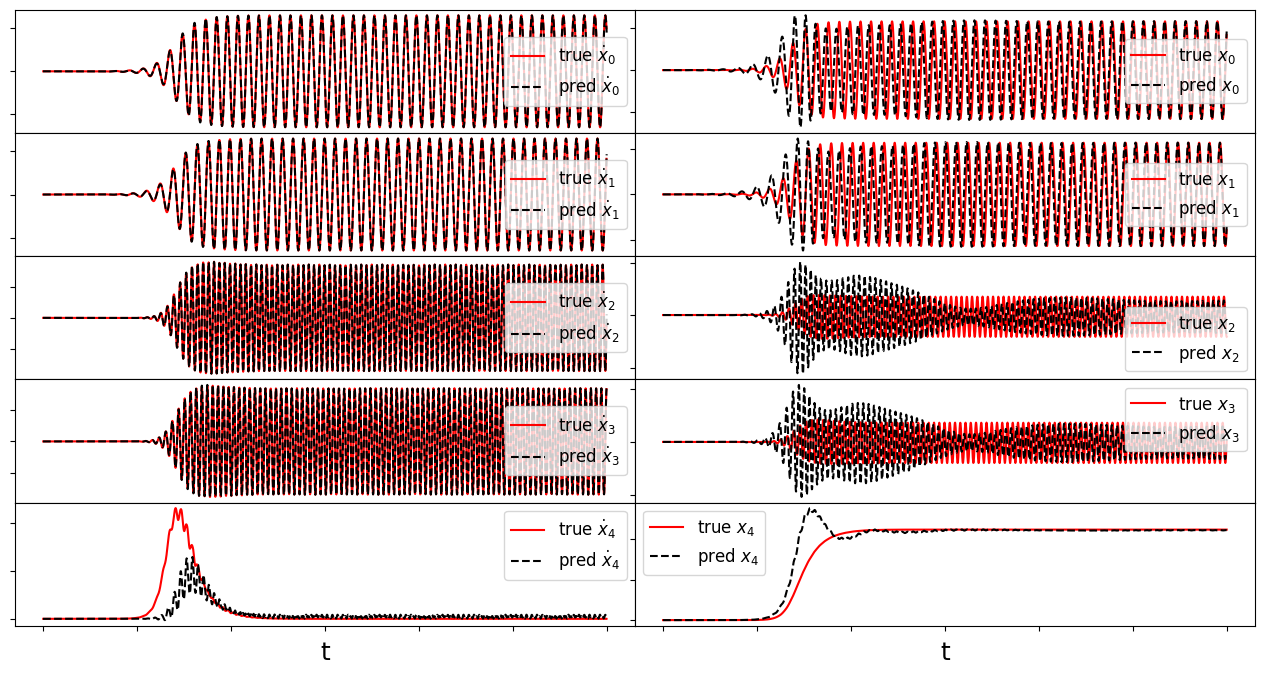
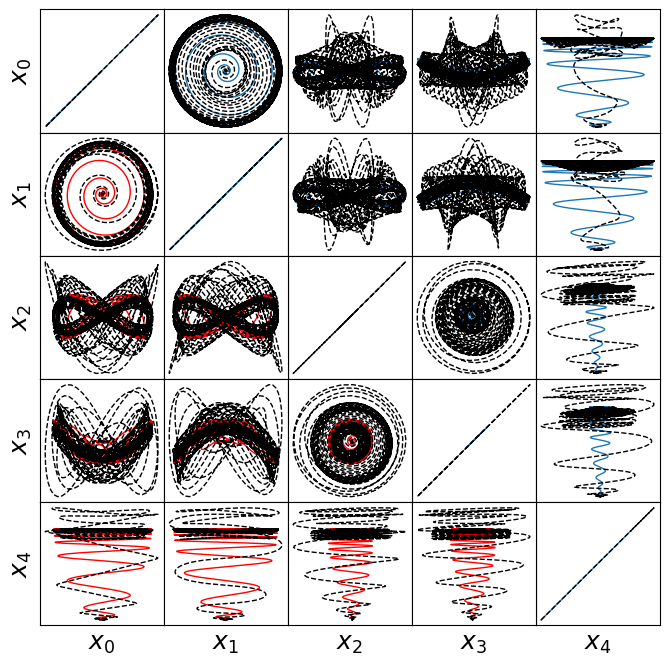
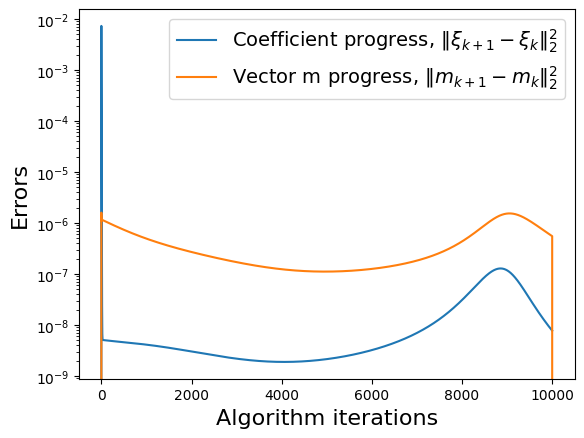
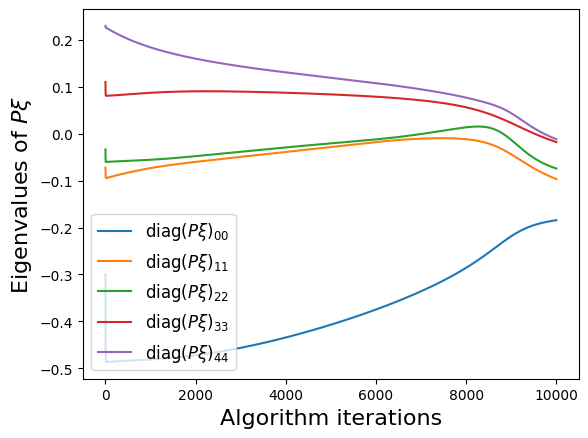
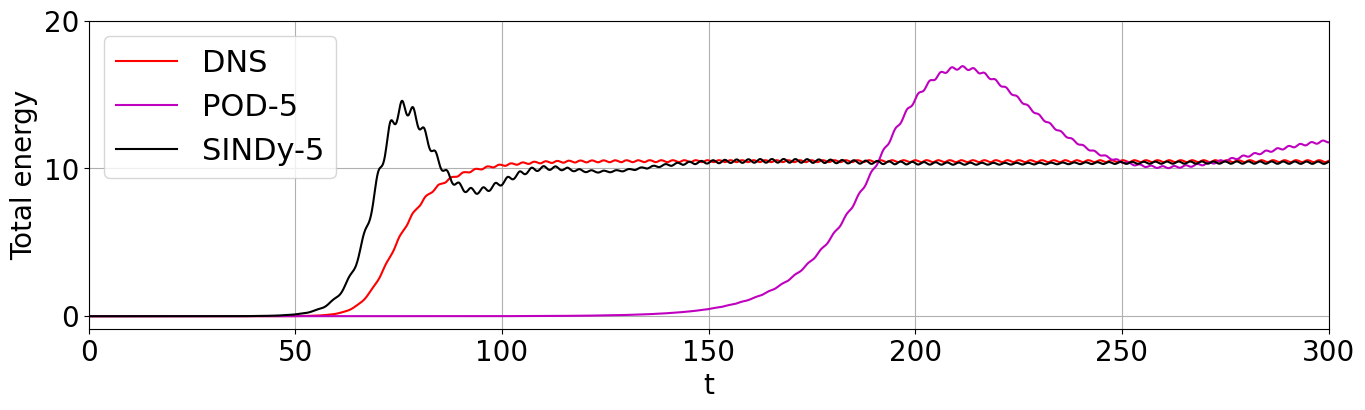
Energy plot illustrating the transient and long-time energy conservation
[13]:
# define energies of the DNS, and both the 5D and 9D models
# for POD-Galerkin and the trapping SINDy models
E = np.sum(a**2, axis=1)
E_galerkin5 = np.sum(a_galerkin5**2, axis=1)
E_sindy5 = np.sum(x_test_pred**2, axis=1)
# plot the energies
plt.figure(figsize=(16, 4))
plt.plot(t, E, "r", label="DNS")
plt.plot(t, E_galerkin5, "m", label="POD-5")
plt.plot(t, E_sindy5, "k", label=r"SINDy-5")
# do some formatting and save
plt.legend(fontsize=22, loc=2)
plt.grid()
plt.xlim([0, 300])
ax = plt.gca()
ax.set_yticks([0, 10, 20])
ax.tick_params(axis="x", labelsize=20)
ax.tick_params(axis="y", labelsize=20)
plt.ylabel("Total energy", fontsize=20)
plt.xlabel("t", fontsize=20)
plt.show()